Українська мова стала лідером за темпами зростання серед ШІ-моделей у 2025 році
Українська мова показала найвищі темпи зростання серед мов, представлених у моделях штучного інтелекту у 2025 році. Про це свідчить аналіз даних платформи Hugging Face, який опублікувало видання AI World. Дослідження охоплює зміни між 2024 і 2025 роками та відображає динаміку розвитку багатомовних ШІ-моделей.
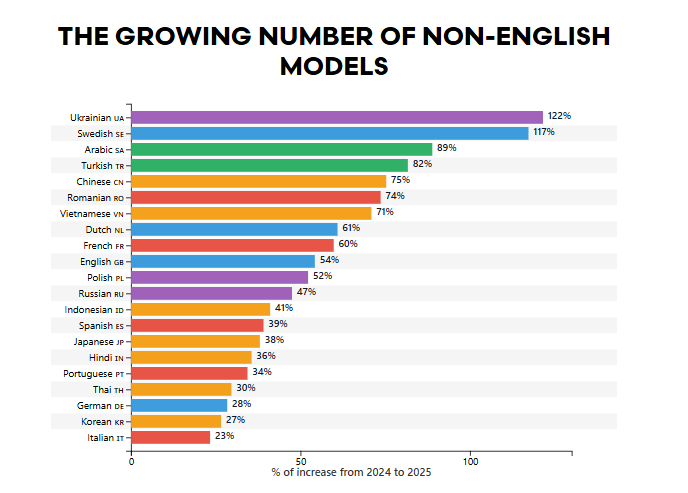
За даними AI World, розвиток штучного інтелекту дедалі активніше відбувається поза межами англомовного середовища. Це пов’язано з ширшою участю різних мовних спільнот у створенні та навчанні моделей, а також зі зростанням відкритих ініціатив у сфері ШІ. Дослідники зазначають, що саме темпи зростання вказують, де інтерес і активність розвиваються найшвидше.
Найвищий річний приріст зафіксовано в українській, шведській, арабській, турецькій та китайській мовах. Ці мови продемонстрували найбільше відсоткове зростання кількості моделей, що свідчить про зміщення фокусу розвитку в бік мов, які раніше були менш представлені в екосистемі штучного інтелекту.
Станом на 2025 рік на платформі Hugging Face зареєстровано майже 270 тисяч моделей з підтримкою англійської мови. Для української мови платформа налічує понад 3 000 моделей та 619 датасетів, що є суттєвим показником для мови, яка донедавна була обмежено представлена в глобальних ШІ-проєктах.
Зростання кількості українськомовних моделей пов’язують з активністю локальної спільноти розробників і дослідників, а також із розвитком відкритих проєктів. Одним із прикладів є Lapa LLM — українськомовна велика мовна модель, яку називають однією з найефективніших для роботи з українською мовою. Її створювали українські дослідники у вільний час, зосереджуючись на якості даних і мовній точності.
Дослідники зазначають, що зростання української мови в екосистемі штучного інтелекту сприяє формуванню більш різноманітного та інклюзивного багатомовного середовища, у якому розвиток ШІ перестає бути зосередженим виключно навколо кількох домінантних мов.
Джерело: dev.ua
