Screaming Frog для РРС: як зробити фід товарів — гайд
Screaming Frog — один із найпотужніших інструментів для SEO-аудиту, але його можливості значно ширші. PPC-фахівці можуть використовувати його для створення товарних фідів без застосування плагінів і залучення розробників, що дає змогу економити час і ресурси.
Я — Аліна Клименко, PPC Specialist у Inweb. У цій статті розповім, як за допомогою Screaming Frog швидко та ефективно створити товарний фід для Google Merchant Center.

Який фід товарів можна зробити за допомогою Screaming Frog
Фід товарів — це структурований файл, який містить інформацію про товари для завантаження в Google Merchant Center.
Фіди для Merchant Center підтримують кілька форматів.
- XML — структурований формат, який найчастіше використовують великі магазини.
- Google Таблиці — зручний варіант для невеликих інтернет-магазинів або ручного редагування даних. Саме цей формат фіда можна зробити за допомогою Screaming Frog.
- TXT (CSV) — текстовий формат із роздільниками, що підходить для простих списків товарів.
Існує два види фідів: основні та додаткові.
Основний фід — це базовий файл, який містить усі ключові дані про товари: назву, опис, ціну, наявність тощо. Він є основним джерелом інформації для Merchant Center. Найчастіше такий фід готують у форматі XML. Проте іноді, зокрема в магазинах із невеликим асортиментом, основний фід може бути у форматі звичайної таблиці. Далі на скрині — те, який вигляд має приклад продуктового фіда від Google Merchant Center.
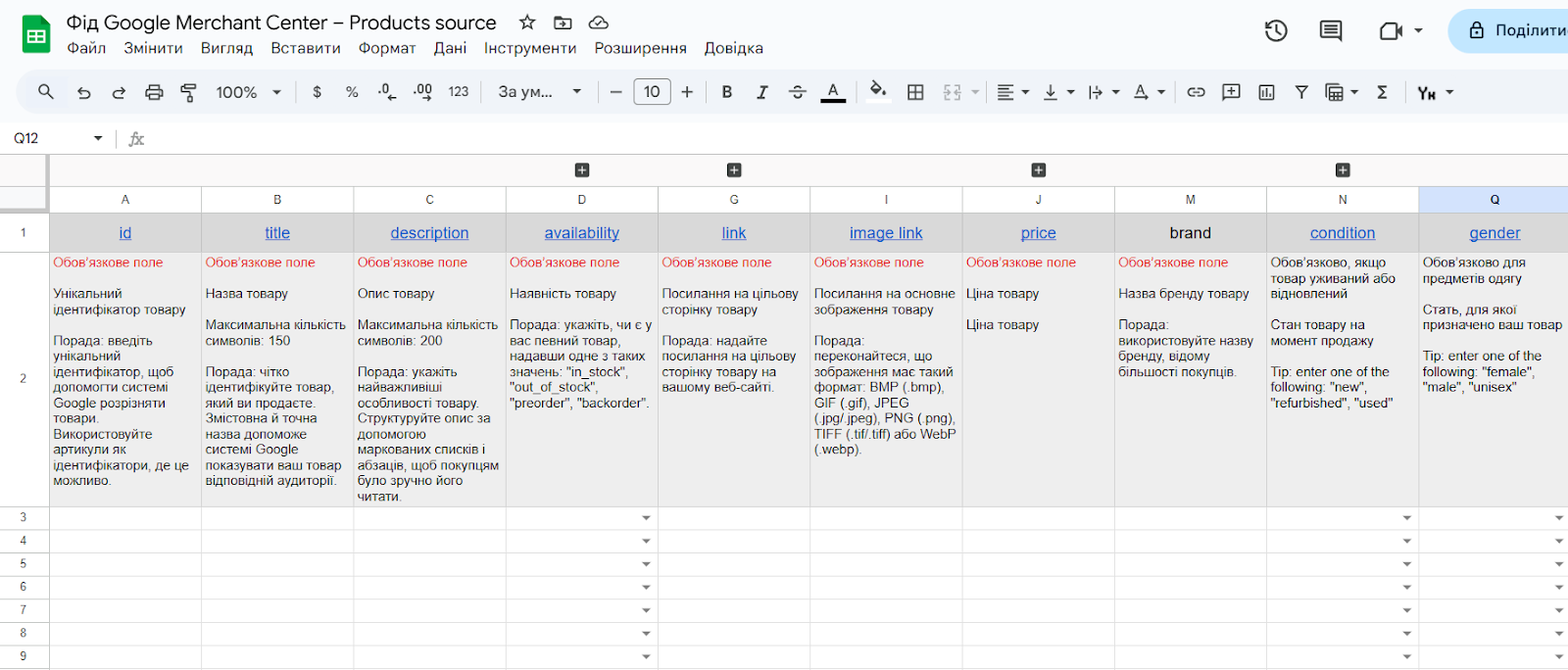
Додатковий фід використовують для оновлення або додавання нових даних до основного фіда. Він може містити, наприклад, акційні ціни, оновлення атрибутів або додаткові описи товарів.
Фід у форматі таблиць можна швидко створити за допомогою Screaming Frog, зібравши дані з сайту та експортувавши їх у форматі Google Sheets або CSV для подальшого завантаження в Merchant Center.
Які кроки треба пройти, щоб створити фід
Покроково покажу вам, як формувати товарний фід, на прикладі магазину годинників BorysenkoWatch.
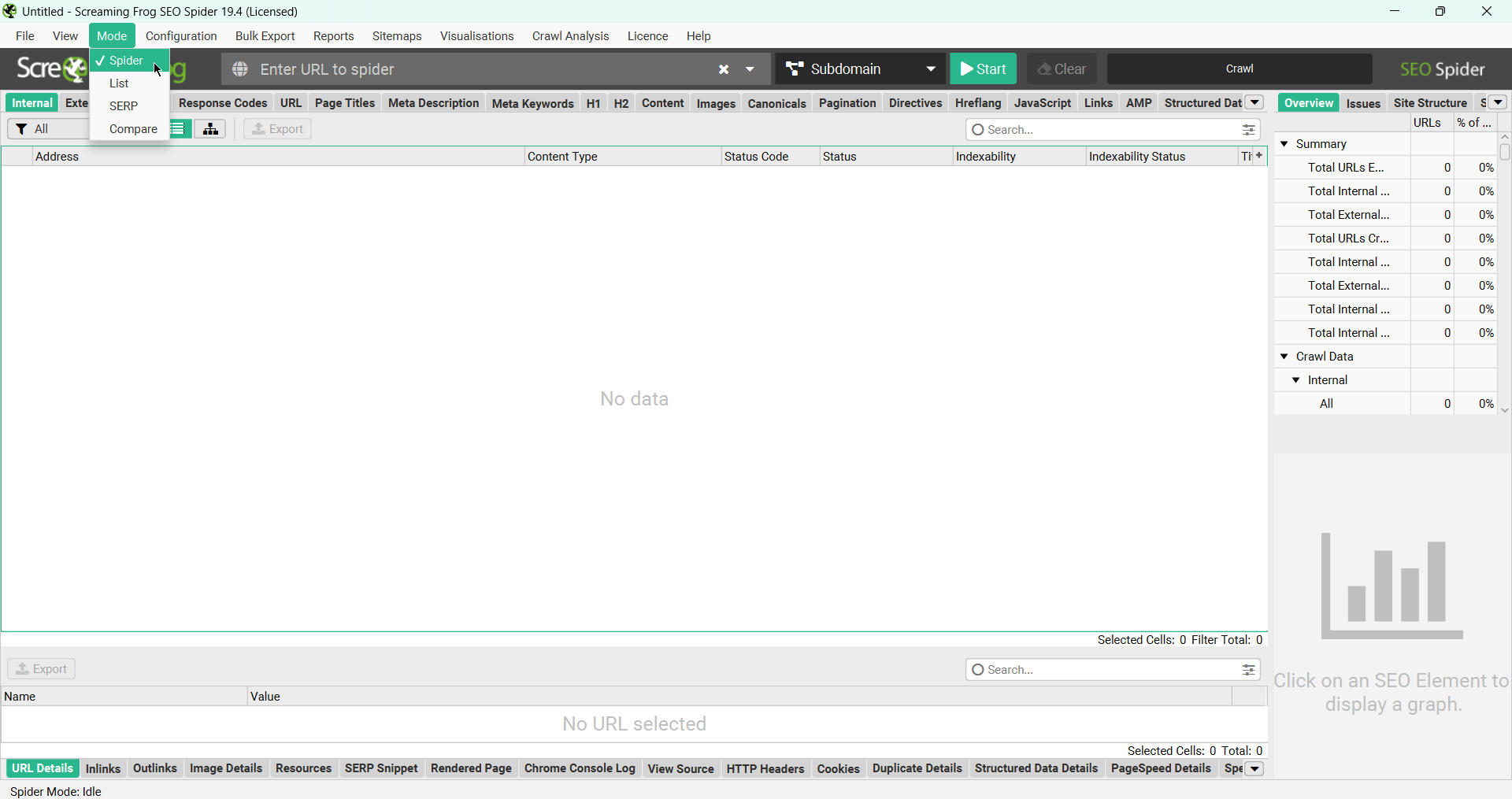
Парсити сайт будемо в режимі Mode > Spider. На скрині показала, де на робочій панелі знайти потрібну кнопку.
У налаштуваннях обов’язково обираємо Configuration > UserAgent > Googlebot.
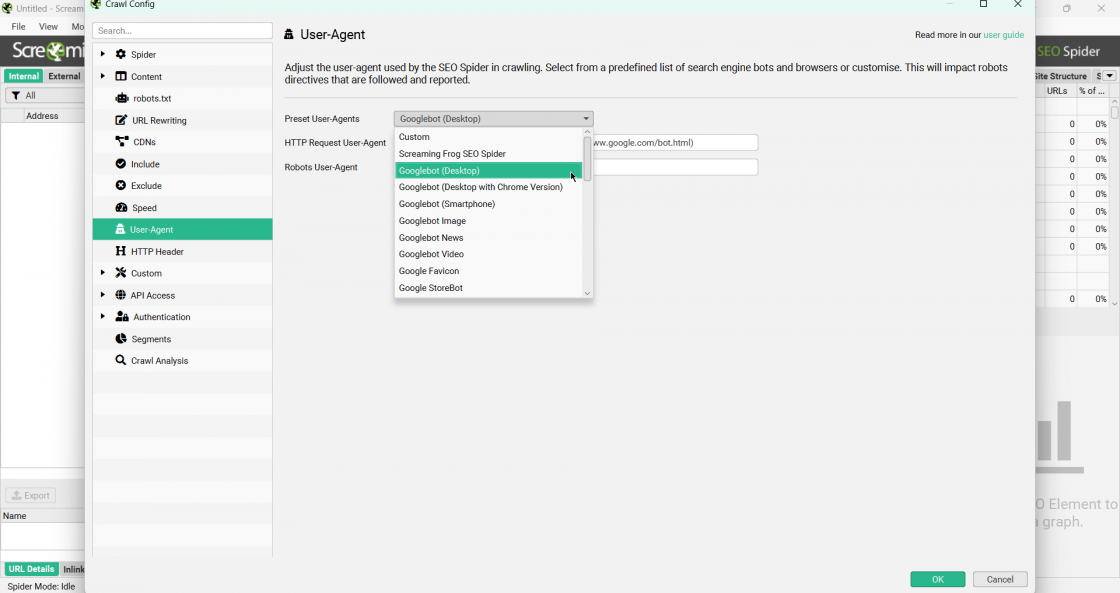
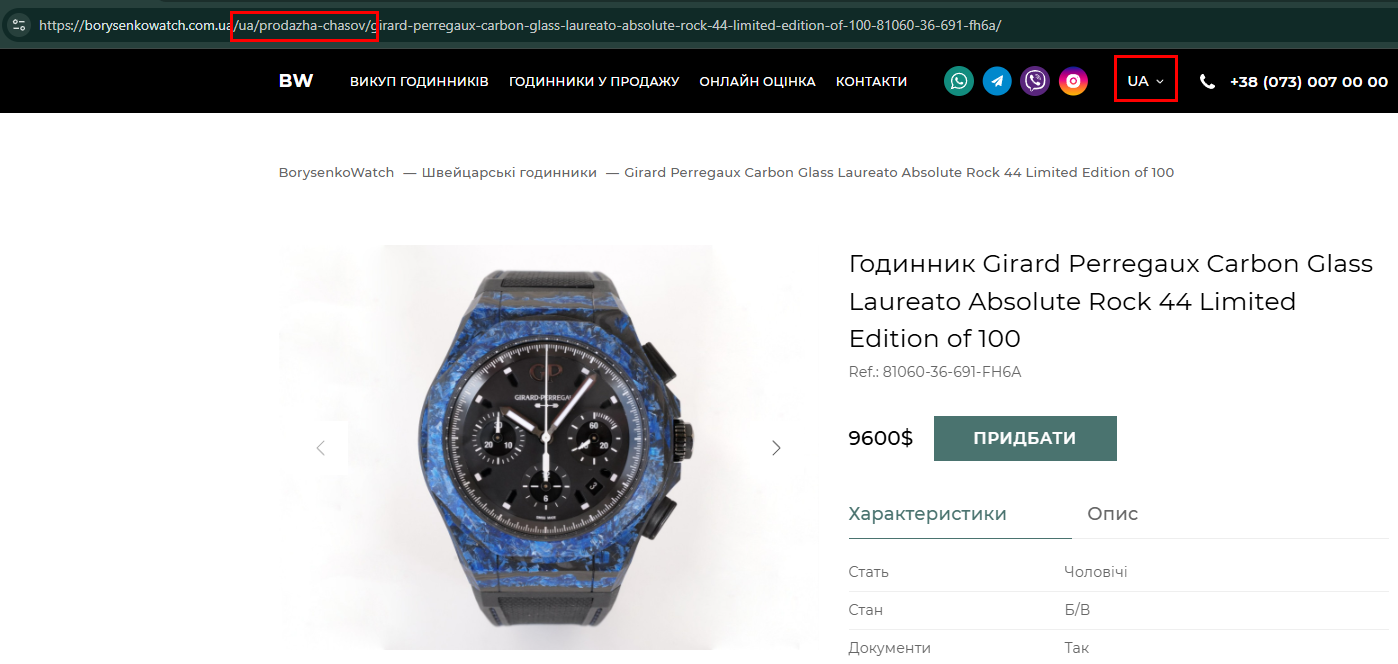
У цьому прикладі нас цікавить формування фіда лише з україномовної версії сайту та лише категорія «Годинники у продажу».
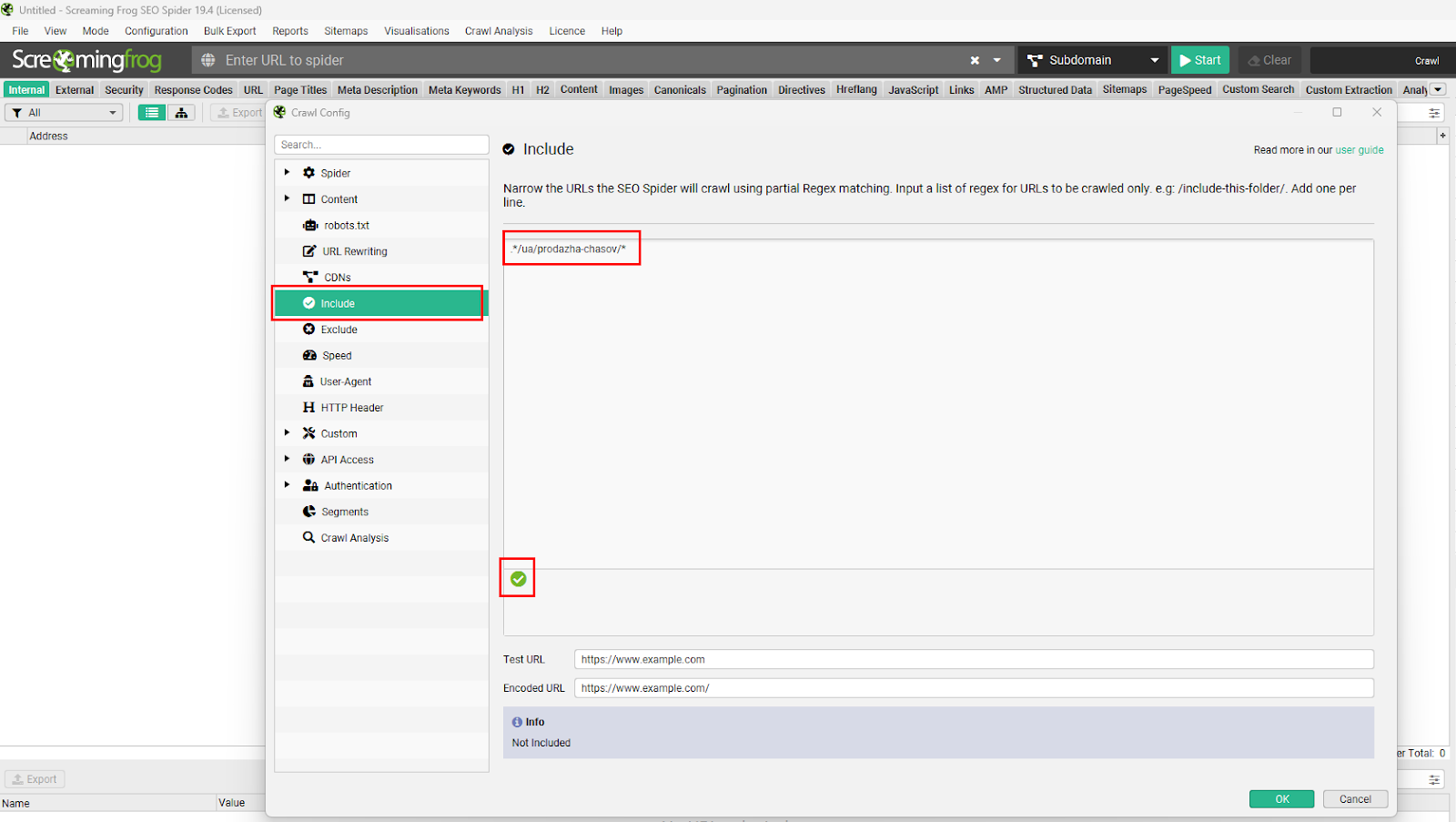
Для того щоб сканувати лише цільові для нас сторінки, додаємо в конфігурацію Include такий регулярний вираз: .*/ua/prodazha-chasov/*. Він означає, що всі URL, що містять цю папку, включаться в парсинг. Зелена галочка внизу означатиме, що ми правильно підібрали вираз.
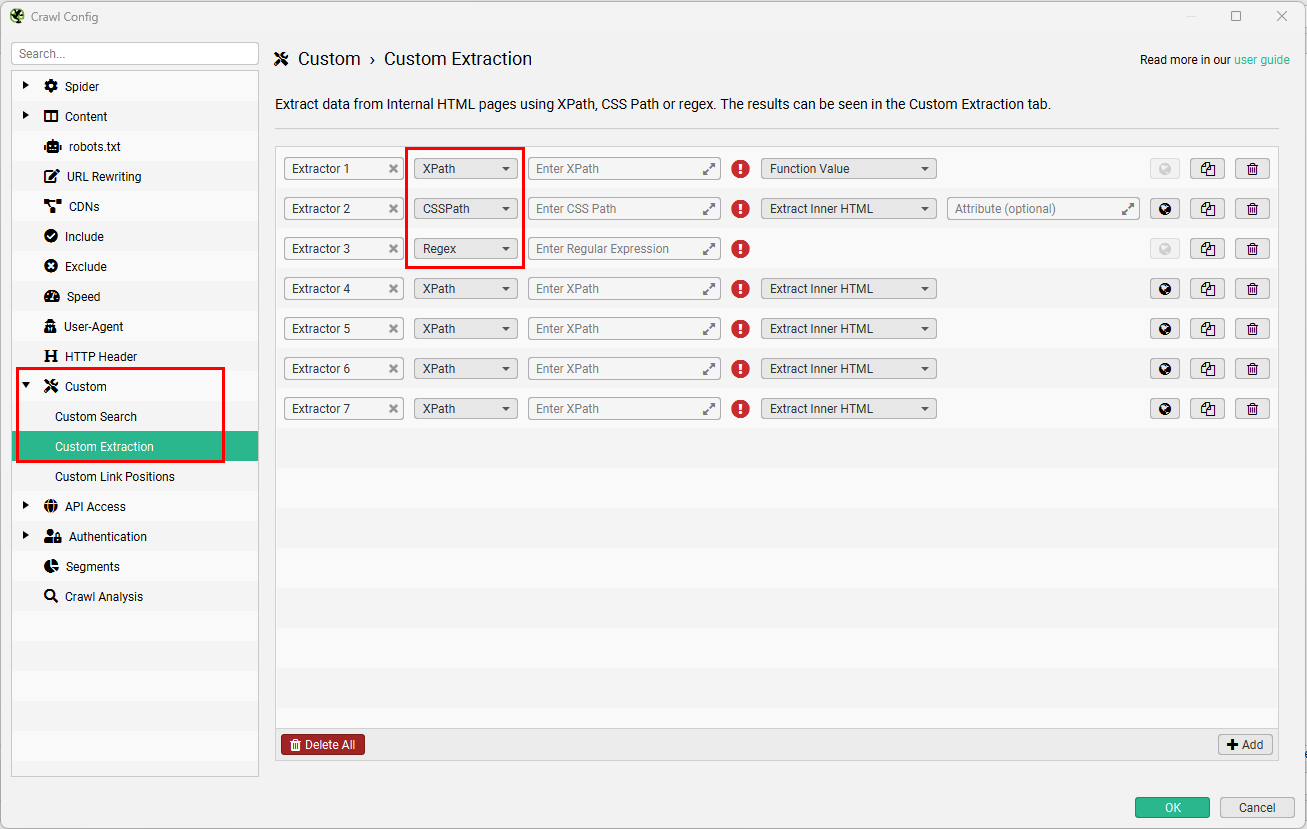
Тепер потрібно налаштувати збір необхідної інформації для торгового фіда, тобто колонок в таблиці. У конфігураціях знаходимо Custom > Custom Extraction. Додаємо необхідну кількість майбутніх атрибутів через +Add.
Налаштовуємо правила вилучення інформації із сайту.
- Назва екстрактора. Даємо назву кожному екстрактору, адже вона відображуватиметься як назва стовпця.
- Методи вилучення. Нам доступно кілька методів вилучення: XPath, CSSPath та Regex.
- Правило. Додаємо регулярний вираз Regex або синтаксис XPath чи CSSPath. Тут все індивідуально для кожного сайту, адже всі мають різну розмітку та структуру.
- Фільтр вилучення. Extract Inner HTML спарсить дані, які містяться всередині тега; Extract HTML Element вилучить елемент повністю з тегами розмітки та його вмістом; Extract Text надасть лише текстову інформацію, а Function Value — числову. Для регулярних виразів Regex фільтр недоступний, а для CSSPath має ще додатковий уточнювальний параметр вилучення.
Тепер починаємо заповнювати правила екстрагування. Для зручності краще давати назву екстрактору, яка аналогічна стандартному фіду: id, title, description, availability тощо.
Для більшості випадків використовуватимемо найпростіший спосіб — метод вилучення XPath. Адже для додавання регулярного виразу потрібні певні знання SQL.
Для того щоб знайти значення елементу XPath, потрібно:
- відкрити сторінку будь-якої стандартної картки товару;
- викликати панель розробника — F12 або через контекстне меню;
- навести на потрібний елемент;
- скопіювати його значення FullXPath;
- вставити його у віконце Enter XPath.
Це буде значення на кшталт /html/body/main/div/article/section/div/div[2]/h1.
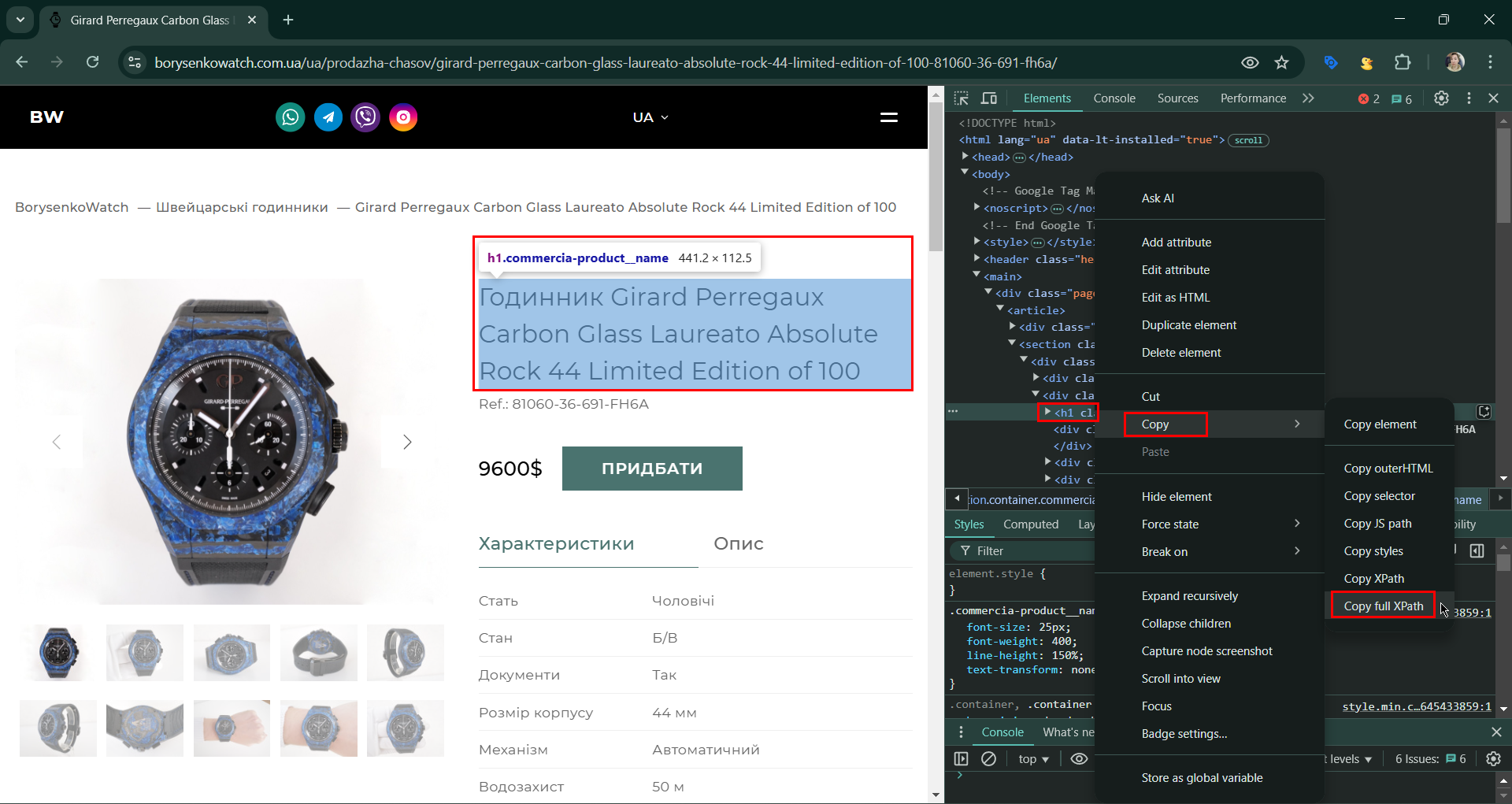
Що треба зробити: копіюємо адресу цього товару та натискаємо кнопку із зображенням планети, яка є навпроти кожного екстрактора. Додаємо наш URL і починаємо тиснути на елемент на сторінці товару, який хочемо спарсити, наприклад title. Він підсвічуватиметься зеленим блоком. XPath цього елементу буде автоматично підібрано й у віконці Source HTML Preview ми побачимо саме те значення, яке потрапить у нашу таблицю під час експорту. Якщо воно з якоїсь причини не підходить, то можна у віконці Suggesrions спробувати інші значення, одразу оцінюючи результат у Source HTML Preview. Якщо інформації тут не буде, то і в таблиці буде пусто.
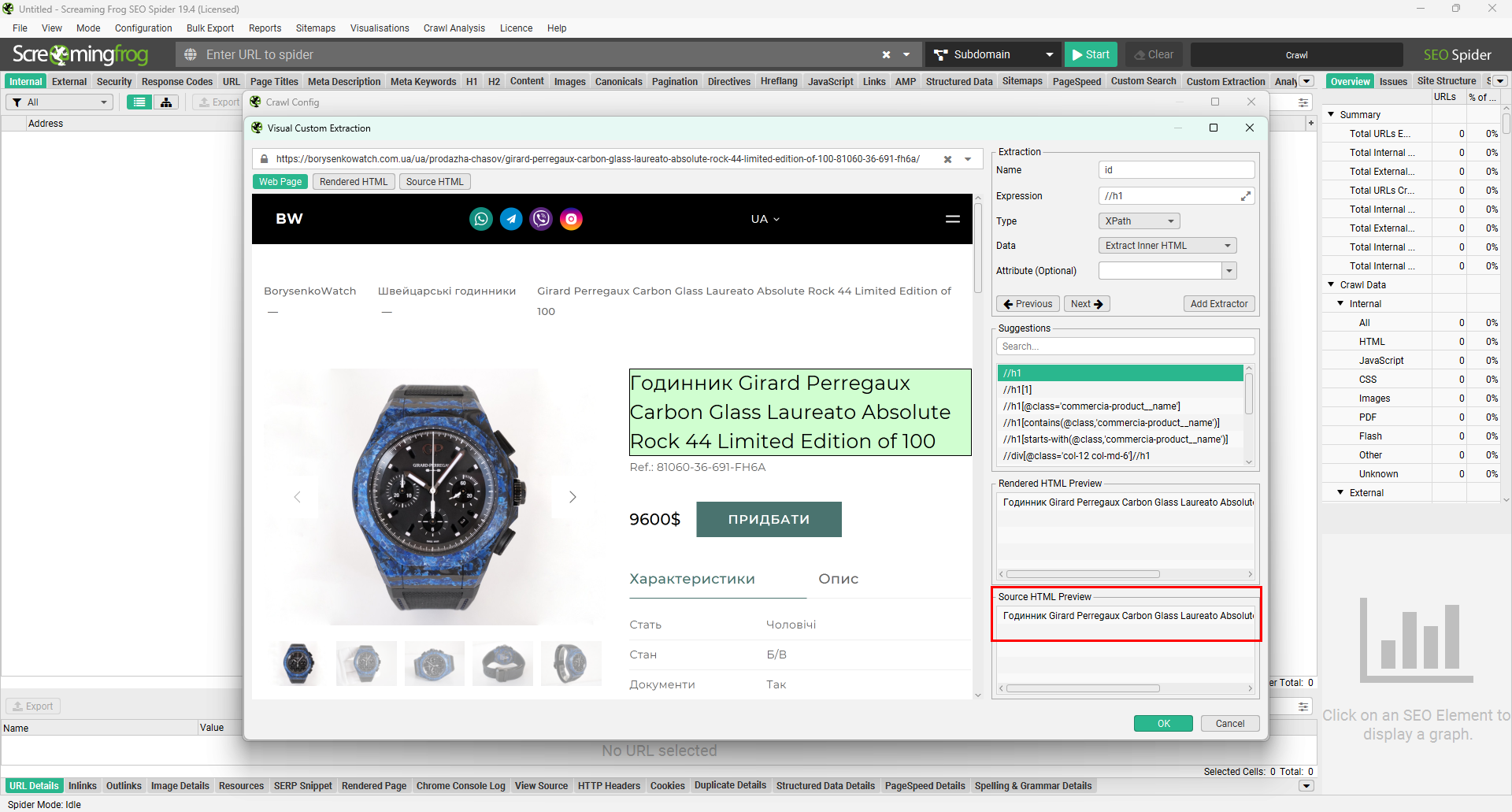
Так само підбираємо значення для інших екстракторів.
На цьому сайті опис складається з кількох абзаців, які є окремими елементами згідно з розміткою Далі на скрині видно, що кожний абзац виділено в окремий блок. Тобто в кожного з них буде свій XPath.
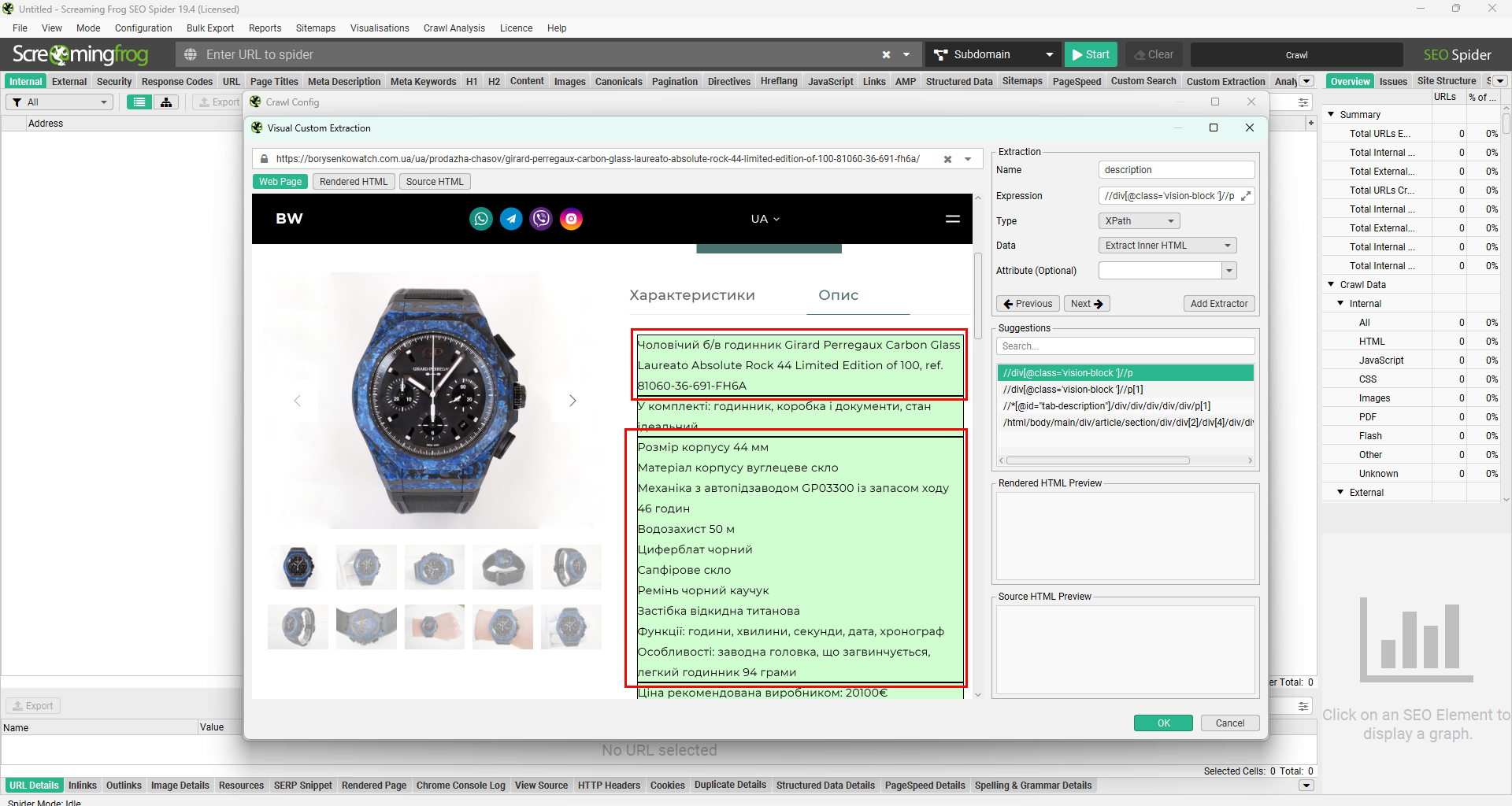
Для того щоб спарсити весь опис, нам потрібно знайти батьківський контейнер вищого рівня так, щоб опис захоплював лише один контейнер.
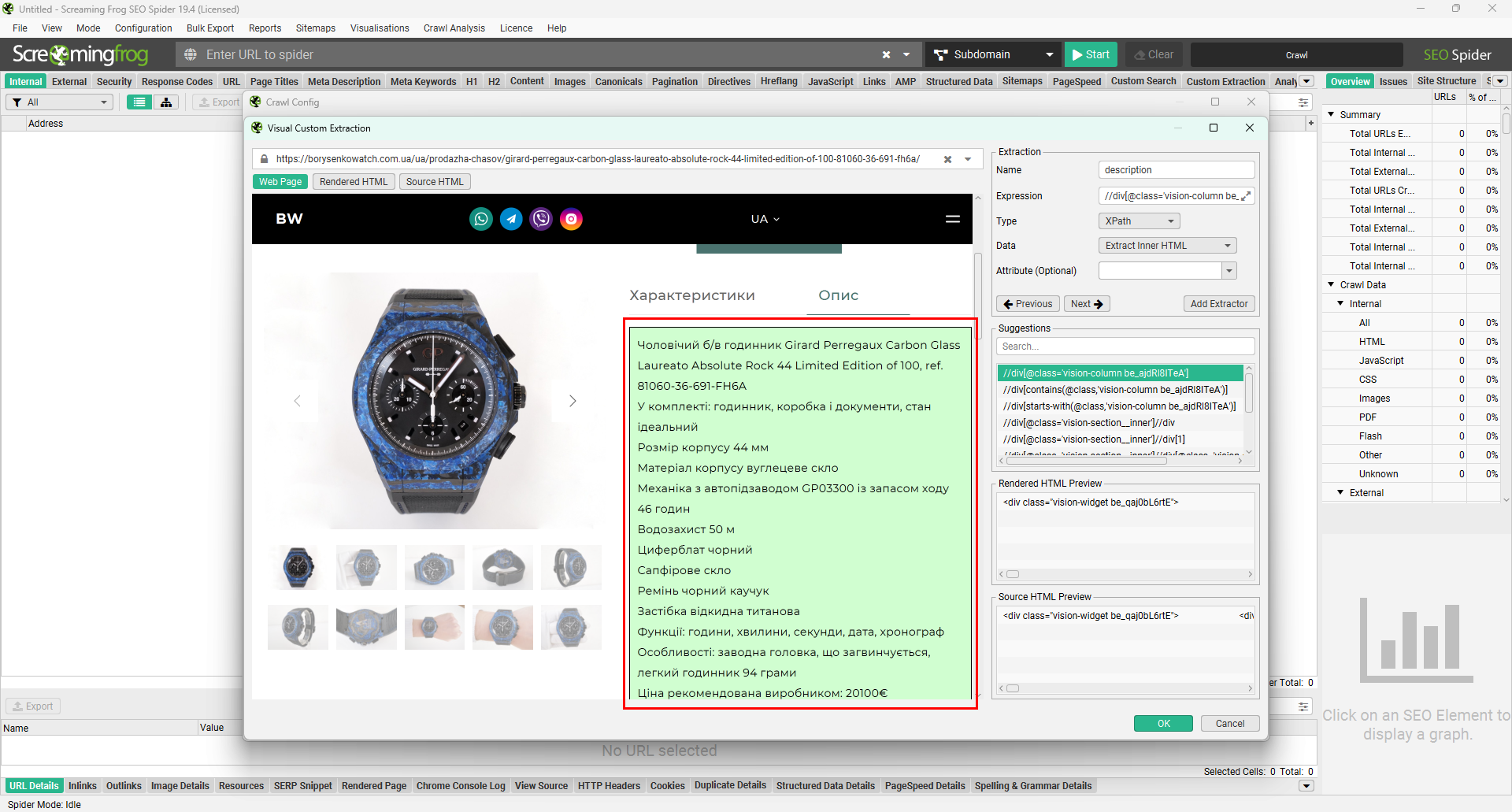
У віконці Source HTML Preview ми побачимо, що якщо екстрагувати з фільтром Extract Inner HTML або Extract HTML Element, то результати міститимуть теги розмітки. Нам це непотрібно, тому просто змінюємо фільтр на Extract Text та отримуємо чистий опис без тегів.
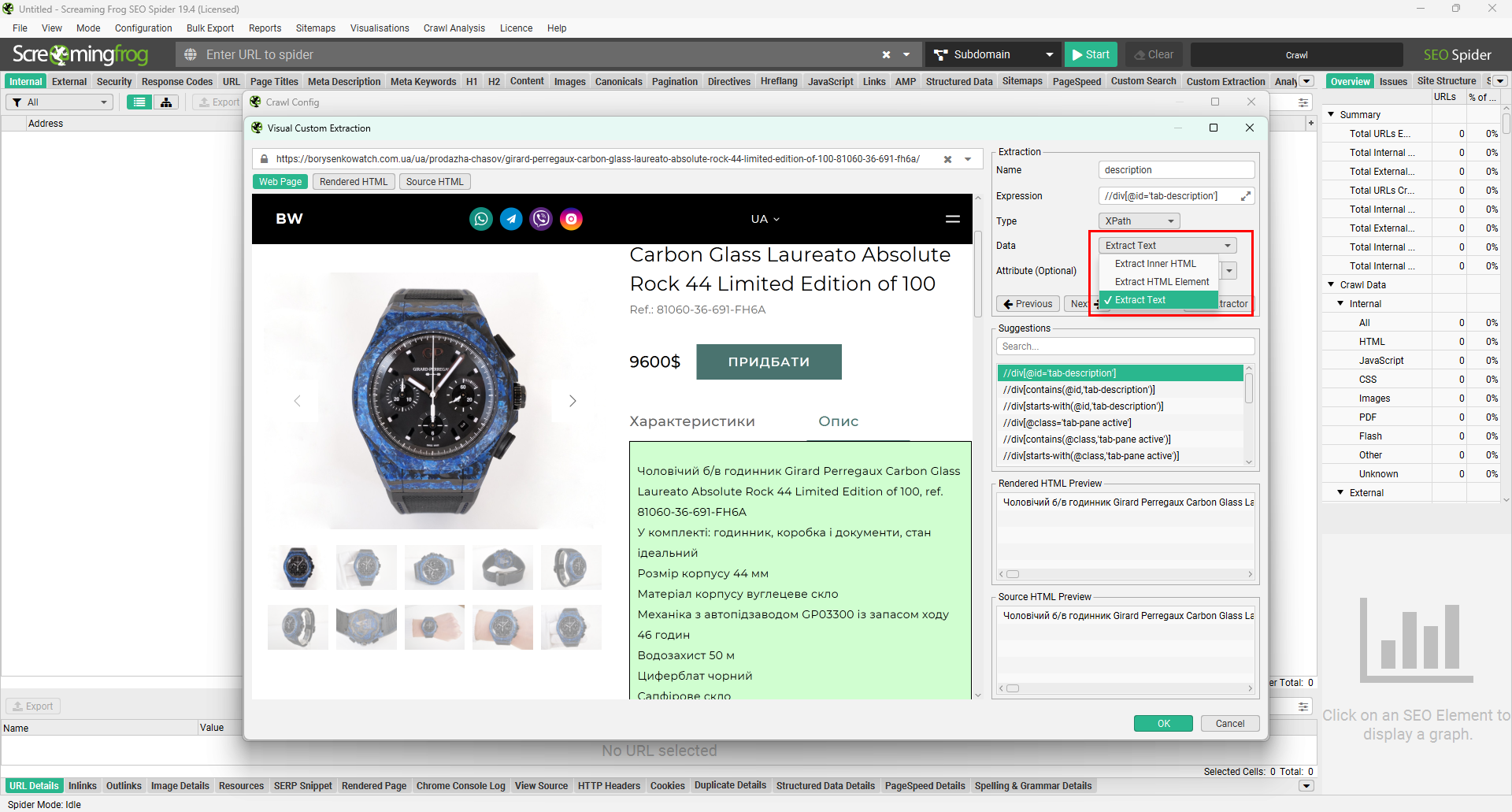
Далі нам потрібно посилання лише на одне перше фото товару. Структура цього сайту така, що якщо ми скопіюємо повний XPath, то не побачимо у вікні Source HTML Preview результату. Отже, у файл експорту наш URL не потрапить.
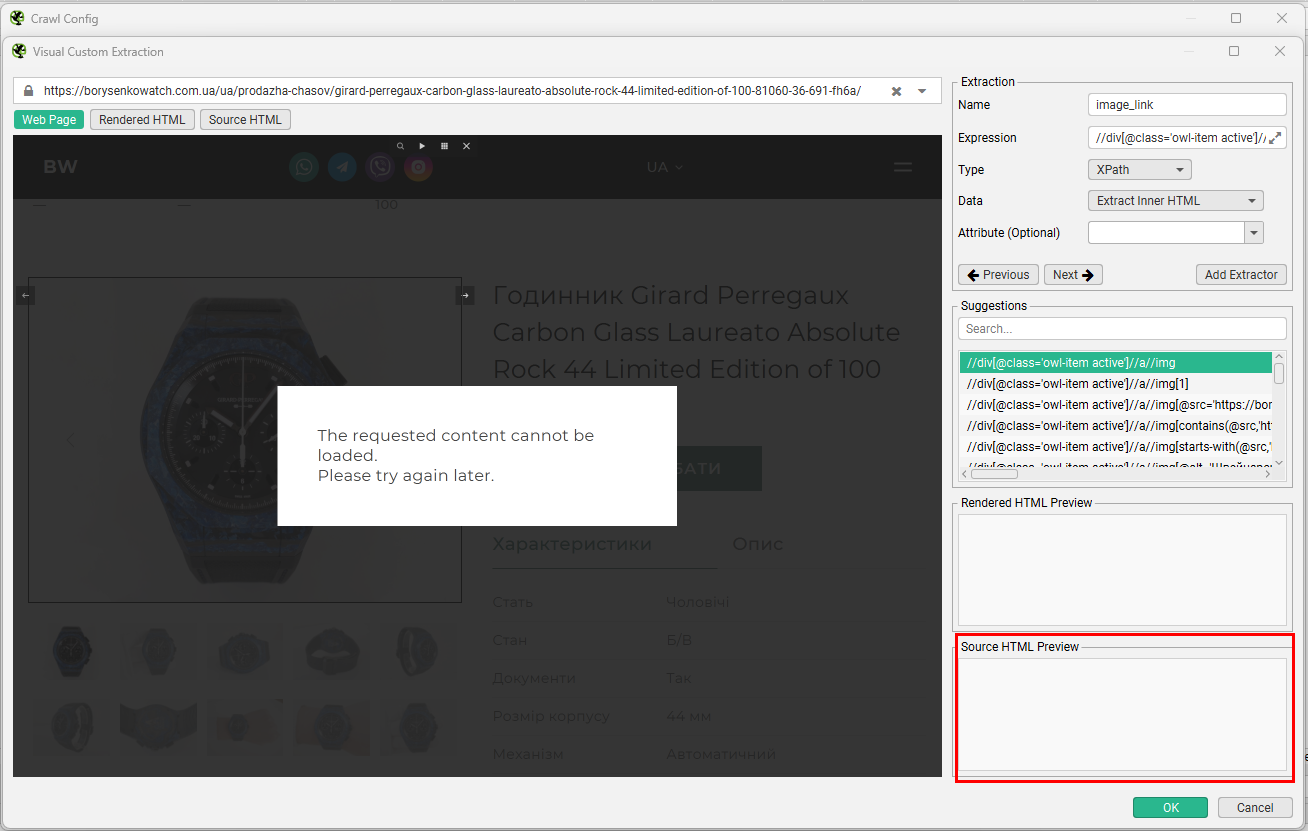
Натискаємо на фото й переходимо у вкладку Source HTML, щоб знайти ідентифікатор. Там бачимо підсвічену зеленим розмітку з нашими фото. Зазвичай це теги <img src=”https://………>. Натискаємо на це посилання та обираємо серед запропонованих значень Suggestions те, яке дасть підходящий результат у Source HTML Preview.
У більшості випадків цей варіант починатиметься з #, адже такий синтаксис мають ідентифікатори стиля CSS. У результатах побачимо посилання з тегами розмітки. Вони нам не потрібні, тому додаємо уточнення src і маємо чисте посилання на фото в результаті.
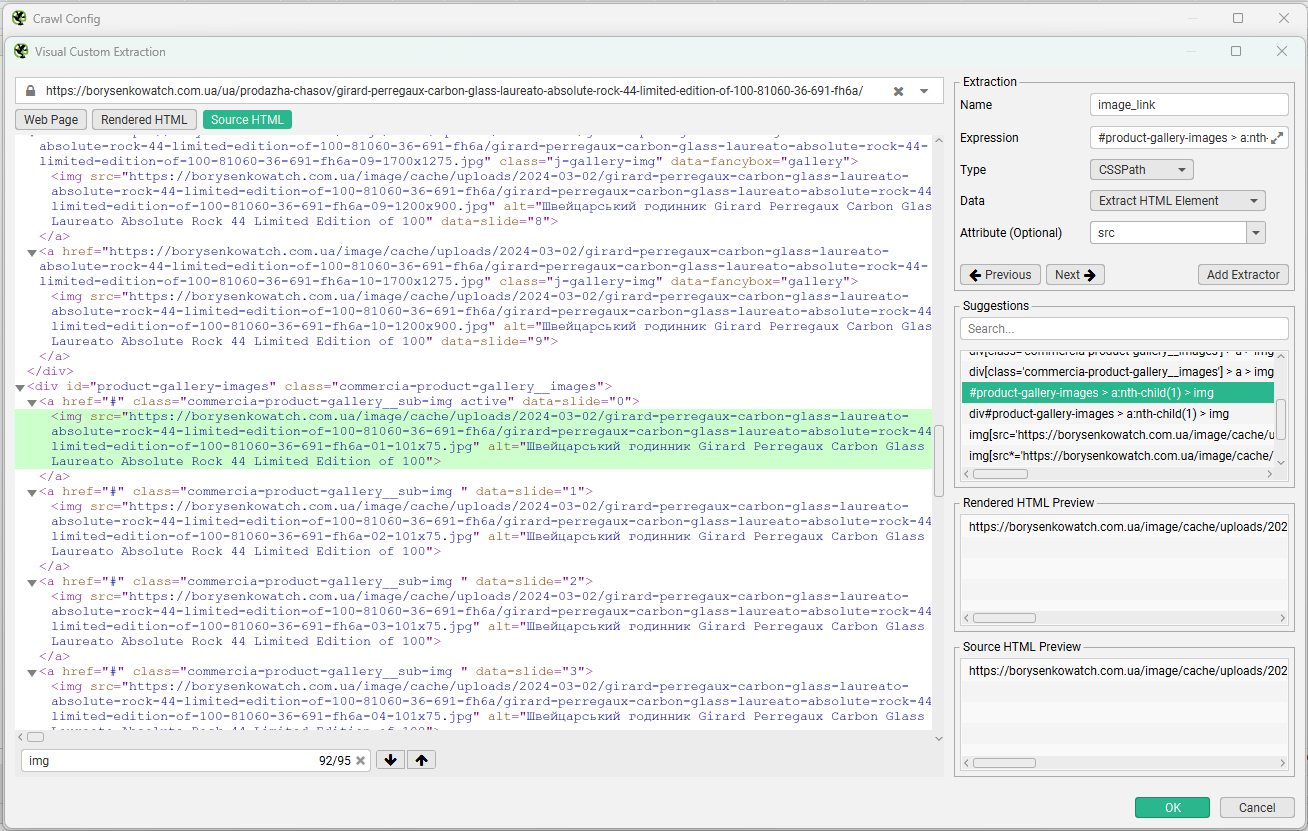
Отже, таким чином можна спарсити більшість елементів із карток товарів для формування товарного фіда для Merchant Center.
Зберігаємо налаштування Custom Extraction і далі краулимо сайт як Subdomain. Наші дані побачимо у вкладці Custom Extraction. Звідси й робимо експорт та працюємо далі в таблицях за необхідності.
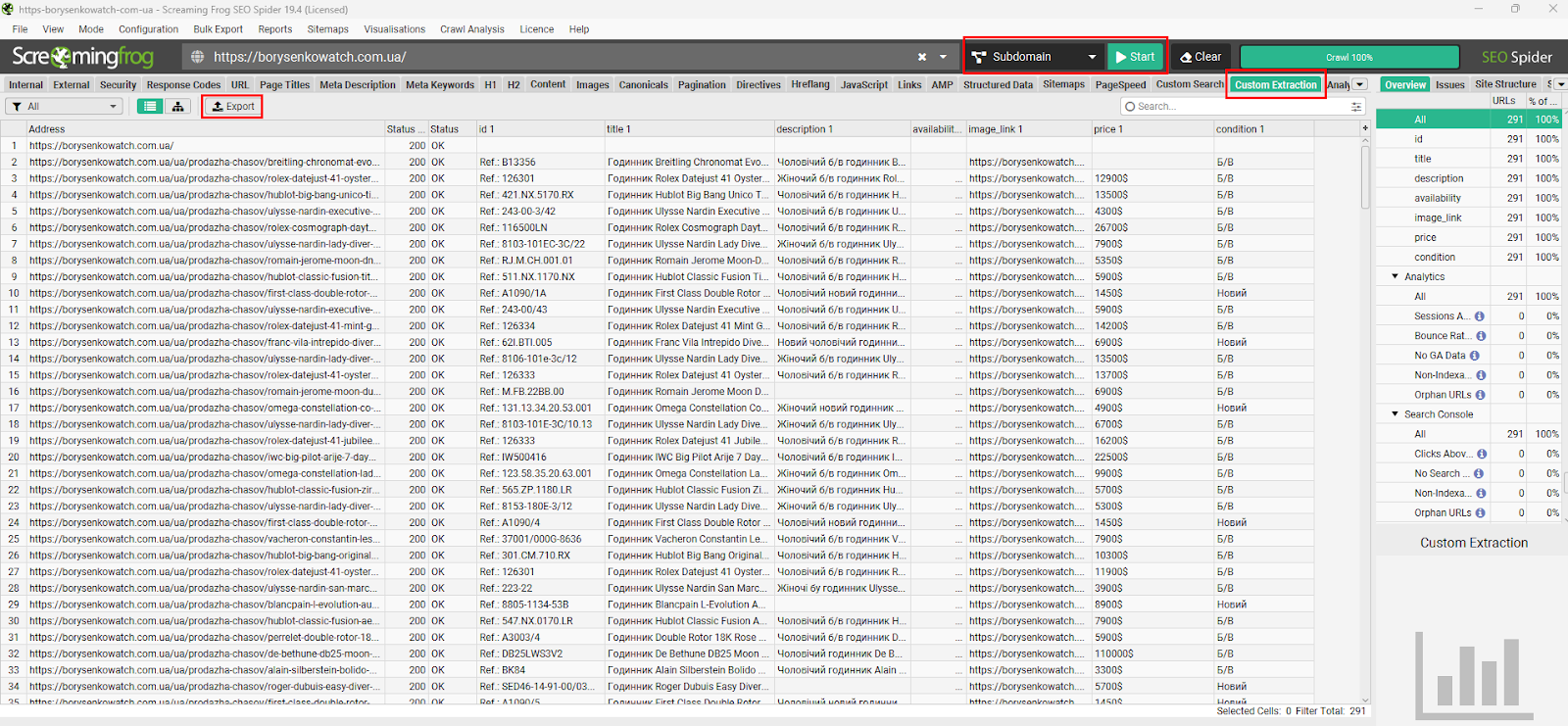
Screaming Frog — не лише інструмент для SEO-аудиту, а й ефективне рішення для PPC-фахівців. Він дає змогу створювати товарні фіди у форматі Google Таблиць без залучення розробників або встановлення плагінів в адмінпанель сайту.
Завдяки можливостям кастомного збору даних можна автоматизувати отримання головних атрибутів для Merchant Center: назви, опису, ціни, фото та наявності товару. Це економить час, забезпечує контроль над якістю фіда та сприяє ефективності рекламних кампаній у Google Merchant Center.

