Що у Perplexity під капотом — розбираємо патерни ранжування й секретну архітектуру клієнтських запитів

Метехан Єсилиюрт, автор блогу Metehan’s Substack, провів глибинне дослідження клієнтських запитів та архітектури пошуку Perplexity й виявив складну криптографічну схему, яка керує оцінкою й ранжуванням контенту через закодовані патерни запитів. Це дослідження пояснює, чому частина контенту отримує необґрунтовані переваги у видачі: додаткові сигнали на рівні запитів лишаються невидимими для стандартних API.
Ми зібрали головні інсайти з дослідження Метехана, які допоможуть краще зрозуміти особливості ранжування в Perplexity й використовувати їх для ефективнішої оптимізації контенту.
Масштаб Perplexity й спосіб споживання контенту
За словами Аравінда Срініваса, CEO та співзасновника, у травні 2025 року Perplexity обробляла близько 780 млн запитів на місяць (≈ 26 млн на день), а загальна база користувачів сягнула близько 30 млн.
Для орієнтиру: за оцінкою дослідження SparkToro на основі панелі Datos, у 2024 році Google обробляла орієнтовно 492 млрд запитів на місяць (≈ 16,4 млрд на день).
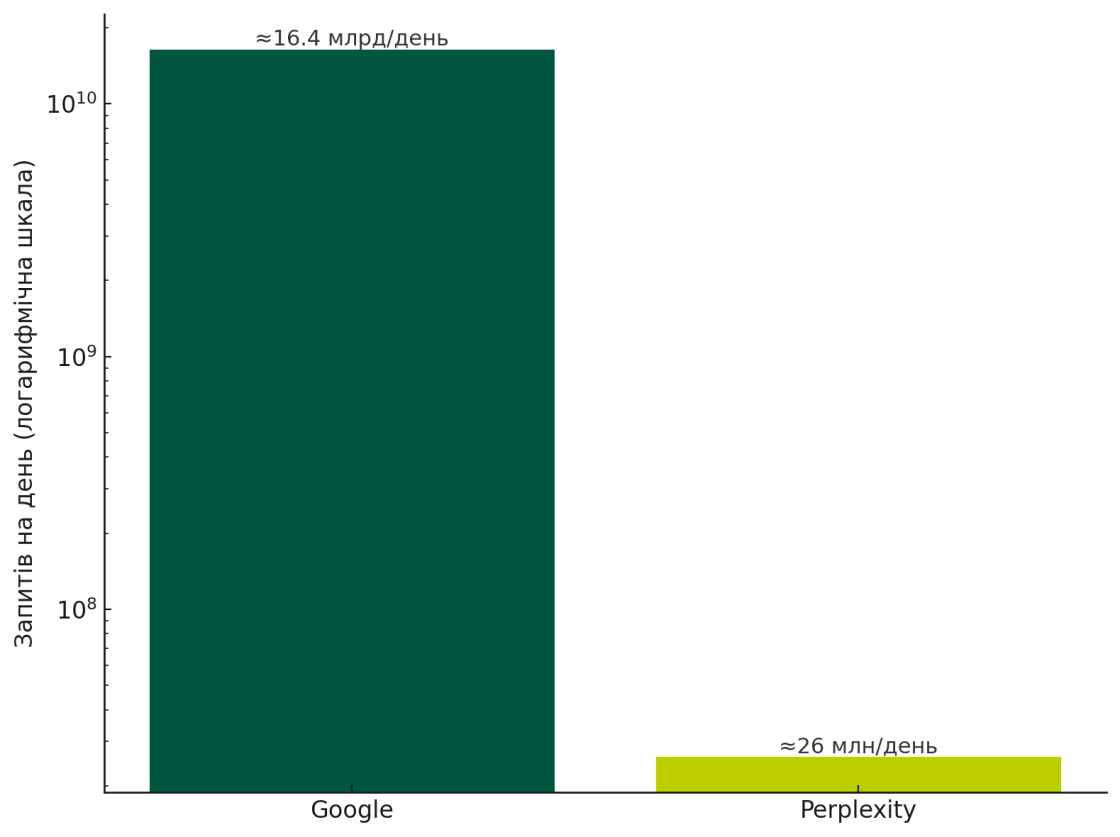
На основі цих даних добовий обсяг Perplexity у травні 2025 року становить близько 0,16% від гуглівського. Це не частка ринку в класичному розумінні, а лише порівняння масштабу платформ. Водночас для нового гравця ринку це вже суттєвий результат і чіткий сигнал, що з Perplexity варто рахуватися.
Не менш важливо й те, як користувачі взаємодіють із платформою: Perplexity активно використовують як мобільний застосунок: версії для iOS та Android синхронізуються між пристроями, а Discover добирає актуальні теми й формує персоналізовану стрічку матеріалів. Це посилює роль Perplexity як каналу дистрибуції контенту, а не лише інструмента класичного пошуку.
Система повторного ранжування Entity Search рівня L3
Perplexity використовує складну тришарову (L3) систему повторного ранжування для пошуку сутностей, що змінює пріоритети конкретних тем, осіб, компаній і концепцій у результатах пошуку. Повторне ранжування працює після початкового вилучення та оцінювання, застосовуючи моделі машинного навчання для підвищення якості результатів.
Система включає механізми захисту від збоїв, які можуть повністю відкидати набори результатів, якщо вони не відповідають стандартам якості, забезпечуючи користувачам показ результатів із високим рівнем достовірності.
Повторне ранжування рівня L3 є критичним барʼєром якості — контент має не лише відповідати пошуковим запитам, а й проходити додаткову оцінку на основі машинного навчання, щоб з’явитися в пошуку за сутностями.
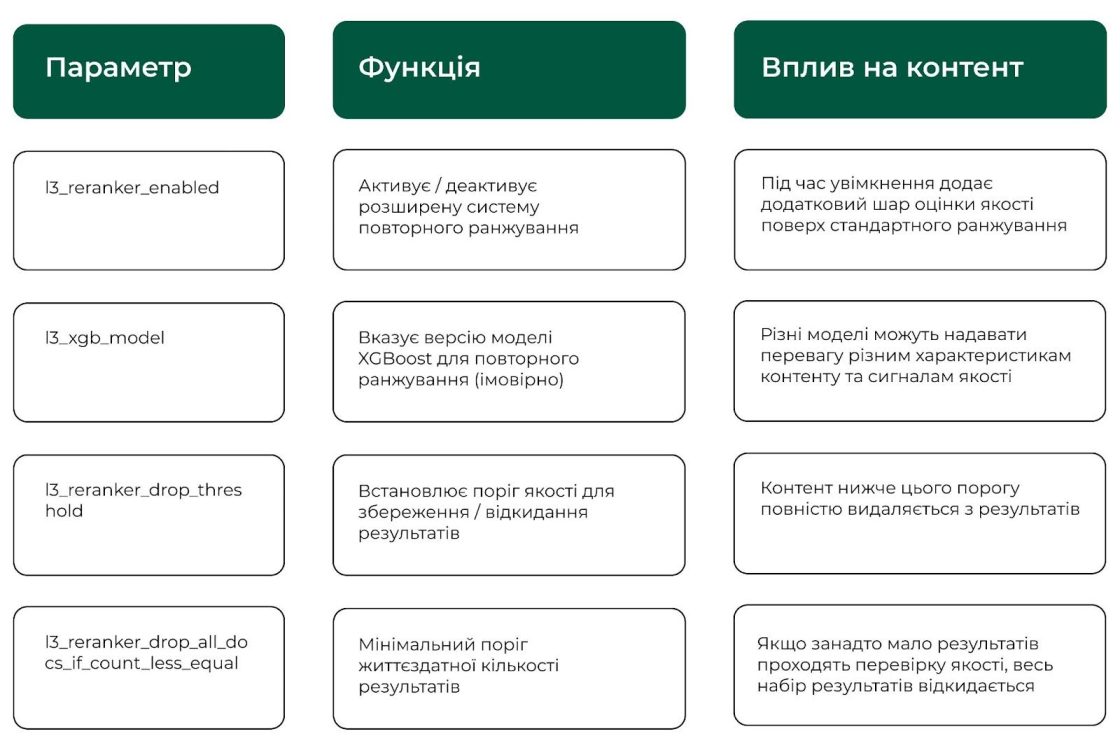
Ця система повторного ранжування пояснює, чому деякий, здавалося б, добре оптимізований контент не з’являється в пошуку за сутностями: він може отримувати високі позиції на початковому етапі, але не проходити перевірку якості повторного ранжування рівня L3. Для того щоб досягнути видачі необхідна не тільки оптимізація за ключовими словами, а й тематична авторитетність та якісні сигнали, що відповідають оцінці машинного навчання.
Налаштування авторитетних доменів: система ручного перевизначення
Одне з найважливіших відкриттів у системі ранжування Perplexity — існування вручну налаштованих авторитетних доменів. На відміну від уявлень про суто алгоритмічний розрахунок авторитету, Perplexity підтримує куровані списки надійних джерел у різних категоріях.
Вибірка авторитетних доменів за категоріями:
- електронна комерція (eCommerce) і покупки — amazon.com, ebay.com, walmart.com, bestbuy.com, etsy.com, target.com, costco.com, aliexpress.com;
- інструменти для продуктивності й професійні платформи — github.com, notion.so, slack.com, figma.com, jira.com, asana.com, confluence.com, airtable.com;
- платформи для комунікації — whatsapp.com, telegram.org, discord.com, messenger.com, signal.org, microsoftteams.com;
- соціальні й професійні мережі — linkedin.com, twitter.com, reddit.com, facebook.com, instagram.com, pinterest.com;
- освітні ресурси — coursera.org, udemy.com, edx.org, khanacademy.org, skillshare.com;
- подорожі й бронювання — booking.com, airbnb.com, expedia.com, kayak.com, skyscanner.net.
“domains”: [
“github.com”,
“gitlab.com”,
“stackoverflow.com”,
“developer.mozilla.org”,
“bitbucket.org”,
“codepen.io”,
“w3schools.com”,
“stackblitz.com”,
“codesandbox.io”,
“repl.it”,
“jsfiddle.net”,
“leetcode.com”,
“hackerrank.com”,
“hackerearth.com”,
“freecodecamp.org”,
“geeksforgeeks.org”,
“gitpod.io”,
“exercism.io”,
“dev.to”,
“css-tricks.com”,
“codecademy.com”,
“frontendmentor.io”,
“codewars.com”,
“glitch.com”
]
Цей ручний відбір означає, що контент, який пов’язаний із перерахованими доменами або посилається на них, отримує органічне підвищення авторитету. Висновок: налагодження співпраці з цими платформами або створення контенту, який органічно включає їхні дані, надає алгоритмічні переваги у видачі.
Стратегія синхронізації заголовків на YouTube
Глибинний аналіз взаємодій показав, що трендові пошукові запити Perplexity безпосередньо впливають на видимість контенту на YouTube. Відео із заголовками, які точно збігаються з цими запитами, отримують суттєві переваги в ранжуванні на обох платформах.
Це створює унікальну можливість для оптимізації: можна відстежувати трендові теми Perplexity і швидко створювати YouTube-контент із заголовками, які точно збігаються. Синхронізація між цими платформами свідчить про глибшу інтеграцію, ніж вважали раніше, де мультимедійний контент, що відповідає трендовим ШІ-запитам, отримує пріоритетне розміщення.
Стратегія працює, тому що Perplexity схоже підтверджує релевантність теми на різних контентних платформах, використовуючи YouTube як сигнал попиту на контент і інтересу користувачів. Цей механізм кросплатформної валідації винагороджує кріейторів, які швидко можуть виявляти й реагувати на нові тренди.
Система пропозицій і картування намірів користувачів
Система пропозицій Perplexity демонструє складну категоризацію намірів користувачів, яка безпосередньо впливає на ранжування контенту. Система групує поведінку користувачів у окремі категорії з конкретними умовами активації:
- завжди активні пропозиції — запити основного функціоналу, що вказують на користувачів із високим наміром;
- пропозиції, що активуються за доменом — запускаються на основі патернів історії переглядів;
- пропозиції на основі порогів активності — потрібний мінімальний рівень активності для активації.
Розуміння цих шаблонів пропозицій дає уявлення про те, як Perplexity передбачає потреби користувачів і відповідно пріоритезує контент. Контент, що відповідає цим запрограмованим категоріям пропозицій, отримує підвищену видимість, оскільки відповідає визначеним намірам користувачів із високою цінністю.
Наслідки для просунутої оптимізації
Аналіз Метехана Єсилиюрта змінює розуміння оптимізації Perplexity:
- стратегія авторитетності доменів — пріоритезувати створення контенту, який органічно включає або посилається на вручну затверджені авторитетні домени;
- синхронізація мультимедіа — розробити систему швидкої реакції для створення YouTube-контенту, що відповідає трендовим пошуковим запитам Perplexity;
- вирівнювання намірів — структурувати контент відповідно до заздалегідь визначених категорій пропозицій і патернів намірів користувачів;
- оптимізація на рівні запитів — урахувати глибші технічні вимоги, що виходять за межі видимої оптимізації контенту.
Відсутність AGI в поточній системі означає, що ці ручні конфігурації та заздалегідь визначені шаблони залишаються стабільними цілями оптимізації. На відміну від суто алгоритмічних систем, які можуть розвиватися непередбачувано, ці патерни надають надійні можливості для оптимізації тим, хто розуміє їхнє значення.
Основні фактори ранжування: фундамент успіху Perplexity
Нова система публікацій
Параметр new_post_impression_threshold є одним із найважливіших факторів у алгоритмі ранжування Perplexity. Коли контент публікується, він потрапляє у ключовий проміжок часу, визначений параметром new_post_published_time_threshold_minutes, протягом якого метрики ефективності визначають його довготривалу видимість.
Ключове відкриття: вимога new_post_ctr створює ситуацію «зробити або зламати» для свіжого контенту. Дописи мають досягти певного рівня залучення протягом цього вікна, щоб претендувати на алгоритмічне підсилення.
Стратегія оптимізації:
- зосередитися на інтенсивних тактиках запуску;
- ретельно відстежувати ранні показники ефективності;
- забезпечити швидку дистрибуцію контенту після публікації;
- спочатку націлюватися на аудиторії з високою активністю.
Множники тем: зміна гри у видимості
Perplexity застосовує різні множники видимості залежно від категоризації контенту:
- subscribed_topic_multiplier — застосовується до контенту в темах, на які користувачі підписані;
- top_topic_multiplier — присвоюється категоріям тем високої цінності;
- default_topic_multiplier — базовий множник для загального контенту.
Важливо: різниця між цими множниками величезна. Контент у топових категоріях отримує експоненціально більшу видимість, ніж контент у категоріях за замовчуванням.
Високочастотні теми:
- штучний інтелект;
- технології та інновації;
- наука й дослідження;
- бізнес та аналітика.
Категорії, яких варто уникати (restricted_topics):
- розважальний контент (низький множник);
- спортивна тематика (низький множник).
У Perplexity ці категорії підпадають під жорсткіші фільтри, що знижують їхню видимість у результатах пошуку.
Зменшення з часом і свіжість контенту (для Discover)
Параметр time_decay_rate створює експоненційне зниження видимості контенту з часом.
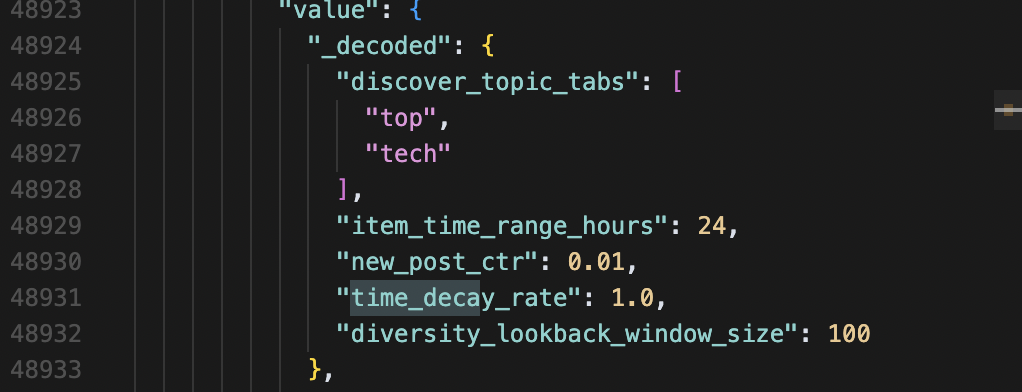
Стратегічні наслідки:
- видимість контенту різко падає після початкової публікації;
- регулярні оновлення та свіжий контент є необхідними;
- частота публікацій має бути з урахуванням закономірностей зниження видимості;
- варто розглядати стратегії оновлення контенту.
Убудовування й семантичний аналіз
Параметр embedding_similarity_threshold виступає якісним фільтром для релевантності контенту. Контент має досягати достатньої семантичної схожості з цільовими запитами, щоб претендувати на ранжування.
Пов’язані системи:
- text_embedding_v1 — основна функція аналізу контенту;
- user_embedding_feature_name — зіставляє контент з інтересами користувача;
- calculate_matching_scores — визначає оцінку релевантності.
Підхід до оптимізації:
- створювати семантично насичений контент;
- використовувати різноманітну лексику та пов’язані поняття;
- забезпечувати всебічне охоплення теми;
- уникати штучного наповнення ключовими словами.
Відстеження залученості користувачів
Perplexity контролює залученість за допомогою кількох складних систем:
- discover_engagement_7d — відстежує тижневі патерни залученості користувачів;
- historic_engagement_v1 — ураховує довготривалу історію ефективності;
- discover_click_7d_batch_embedding — аналізує патерни кліків.
Оптимізація залученості:
- зосередитися на створенні привабливих заголовків;
- переконатися, що контент відповідає очікуванням користувачів;
- оптимізувати для довшого часу перебування на сторінці;
- заохочувати повторні візити.
Пам’ять і мережі контенту
Система boost_page_with_memory винагороджує взаємопов’язаний контент, який розвиває попередні теми. Це створює ефект мережі, де пов’язаний контент працює ефективніше разом.
Стратегії побудови мережі:
- створювати серії контенту на пов’язані теми;
- нативно посилатися на попередні матеріали;
- формувати тематичний авторитет через кластери;
- підтримувати узгоджені тематичні напрями.
Просунуті фактори ранжування
Керування стрічкою та розподіл
Параметр persistent_feed_limit контролює кількість контенту, що з’являється у стрічках користувачів, тоді як feed_retrieval_limit_topic_match визначає видимість контенту за конкретними темами.
Ключові компоненти:
- persistent_feed_cache_ttl_minutes — тривалість кешування контенту в стрічці;
- persistent_feed_time_buffer_minutes — часовий проміжок для включення контенту в стрічку;
- enable_new_persistent_feed — активація покращених алгоритмів роботи зі стрічкою.
Фільтрація контенту й контроль якості
Кілька систем запобігають появі низькоякісного або повторюваного контенту:
- viewed_items_filter_limit — запобігає показу вже переглянутого контенту;
- enable_search_urls_based_dedup — усуває дублікати контенту;
- viewed_pages_ttl_secs — відстежує тривалість історії переглядів.
Негативні сигнали та штрафи
Perplexity активно фільтрує контент на основі негативного зворотного зв’язку від користувачів:
- dislike_filter_limit — максимальна кількість «невподобань» перед фільтрацією;
- enable_dislike_embedding_filter — активує фільтрацію на основі подібності;
- dislike_embedding_filter_threshold — чутливість виявлення «невподобань»;
- discover_no_click_7d_batch_embedding — відстежує контент, якого користувачі уникають.
Вимоги до хештегів і різноманіття
Параметр diversity_hashtag_similarity_threshold гарантує різноманітність контенту:
- user_hashtag_feature_name — відстежує вподобання користувачів щодо хештегів (Discover Feed Topics);
- hashtag_match_threshold — визначає релевантність хештегів (Discover Feed Topics);
- blocked_hashtags — заборонені системою теги (Discover Feed Topics).
Система Blender
Різноманіття контенту в стрічках керується за допомогою:
- blender_web_link_percentage_threshold — обмежує щільність зовнішніх посилань;
- blender_web_link_domain_limit — обмежує домінування одного домену;
- blender_web_link_domain_sliding_window_size — часовий інтервал для відстеження доменів;
- enable_new_blender_flow — активує покращені алгоритми змішування.
Технічна інфраструктура
Моделі ранжування й прогнозування:
- enable_ranking_model — активує ранжування на основі штучного інтелекту;
- ranking_model_name — вказує версію активної моделі;
- prediction_model_names — доступні моделі прогнозування;
- enable_ranking_by_model_score — пріоритезує оцінки від ШІ.
Логування та аналіз:
- enable_logging — активує відстеження продуктивності;
- items_for_logging_limit — максимальна кількість об’єктів для відстеження;
- enable_filtered_item_ids_logging — відстежує відфільтрований контент.
Система Union Retrieval
Система enable_union_retrieval об’єднує кілька джерел даних для комплексних результатів, покращуючи пошук контенту в різних контекстах.
Двигун рекомендацій запитів: технічна реалізація
Важливе відкриття в інфраструктурі Perplexity виявляє складну систему рекомендацій запитів із такою структурою конфігурації:
{
“trending_news_enabled”: [boolean],
“trending_news_index_name”: “[індекс_ідентифікатор]”,
“trending_news_minimum_should_match”: [поріг_значення],
“trending_news_block_words”: [масив_заборонених_термінів],
“suggested_enabled”: [boolean],
“suggested_index_name”: “[ідентифікатор_індексу]-[версія]”,
“suggested_num_per_cluster”: [розмір_кластера],
“suggested_block_words”: [масив_заборонених_термінів],
“fuzzy_dedup_threshold”: [відсоткове_значення],
“fuzzy_dedup_enabled”: [boolean],
“autosuggest_enabled”: [boolean]
}
Ця конфігурація показує, як Perplexity використовує кілька спеціалізованих індексів для різних типів запитів. Параметр trending_news_index_name вказує на окремий індекс, який відстежує в реальному часі пошукові патерни, тоді як suggested_index_name відповідає за загальні рекомендації запитів з суфіксами контролю версій.
Інтелект системи базується на кількох ключових механізмах.
Виявлення трендів. Параметр trending_news_minimum_should_match встановлює поріг для підсилення запитів. Коли кількість пошуків перевищує цей поріг, запити переходять зі статусу звичайних у трендові, що активує підвищену видимість.
Логіка дедуплікації — fuzzy_dedup_threshold у поєднанні з fuzzy_dedup_enabled запобігають фрагментації запитів.
if (fuzzy_dedup_enabled && similarity_score > fuzzy_dedup_threshold) {
// Запити вважаються дублікатами
// Об’єднуються в основний варіант запиту
}
Архітектура кластера. Параметр suggested_num_per_cluster визначає, як групуються пов’язані запити.
query_clusters = {
primary_query: “основний пошуковий термін”,
related_queries: [
// До suggested_num_per_cluster пов’язаних термінів
]
}
Фільтрація заборонених слів: і трендова, і рекомендована системи використовують масиви block_words.
if (!trending_news_block_words.includes(query_term) &&
!suggested_block_words.includes(query_term)) {
// Запит підходить для рекомендації
}
Функціонал автозаповнення: (autosuggest_enabled) працює як накладка на ці системи, створюючи трирівневу архітектуру:
- зіставлення базових запитів;
- кластеризація пропозицій;
- відображення автозаповнення.
Ця технічна структура пояснює, чому деякі запити раптово набувають популярності — вони проходять кілька рівнів перевірки й перевищують встановлені пороги. Кріейтори, які розуміють ці параметри конфігурації, можуть краще передбачити, які теми отримають алгоритмічне підсилення, і відповідно планувати створення контенту.
Відокремлення параметрів trending_news_ та suggested_ свідчить про різні шляхи оптимізації: один для чутливого до часу новинного контенту, другий — для вічнозелених тем. Успіх вимагає розуміння, у якому індексі ймовірніше з’являться цільові запити, і відповідної оптимізації.
Стратегії оптимізації на 2025 рік
Оптимізація стратегії запуску
- Максимізувати раннє залучення — зосередитися на критичному вікні після публікації.
- Орієнтуватися на високочастотні теми — узгоджувати контент із топовими категоріями.
- Швидко нарощувати залученість — досягати порогів показів максимально швидко.
Кращі практики структурування контенту
- Семантична насиченість — перевищувати вимоги до семантичної схожості.
- Всеохоплююче висвітлення — дати повні відповіді на запитання.
- Натуральна мова — уникати штучної оптимізації.
- Свіжі погляди — надавати унікальні інсайти.
Тактики побудови мережі
- Тематичні кластери — формувати взаємопов’язаний контент.
- Пам’ять і зв’язки — нативно посилатися на пов’язаний контент.
- Розвиток авторитету — системно бути експертом.
Уникнення штрафів
- Відстежувати негативні сигнали — контролювати відгуки користувачів.
- Підтримувати різноманітність — варіювати хештеги й теми.
- Якість понад кількість — зосереджуватися на користі для користувача.
- Свіжий контент — регулярні оновлення протидіють зниженню видимості.
Зведена таблиця: фактори ранжування Perplexity

Резюмуємо
Розуміння факторів ранжування Perplexity дає значну конкурентну перевагу в пошуковому середовищі 2025 року, яке працює на основі ШІ. Для успіху потрібні:
- стратегічний вибір тем — зосереджуватися на високочастотних темах;
- швидкі тактики запуску — максимізувати раннє залучення;
- побудова мережі контенту — створювати взаємопов’язану цінність, органічно посилаючись на повʼязані матеріали;
- безперервна оптимізація — адаптуватися до змін алгоритмів;
- якість замість маніпуляцій — надававати реальну користь користувачам.
Сайти, які домінують у Perplexity, розуміють ці фактори та відповідно узгоджують свої стратегії. Систематичне впровадження цих інсайтів допоможе досягти успіху в пошуку на базі ШІ, що постійно розвивається.
Хоча конкретні пороги й значення можуть змінюватися з часом, основні принципи залишаються сталими: створювати цінний, своєчасний, добре пов’язаний контент, який задовольняє потреби користувачів в епоху пошуку на базі ШІ.
