OpenAI навчає ШІ-моделей визнавати помилки й описувати свої дії
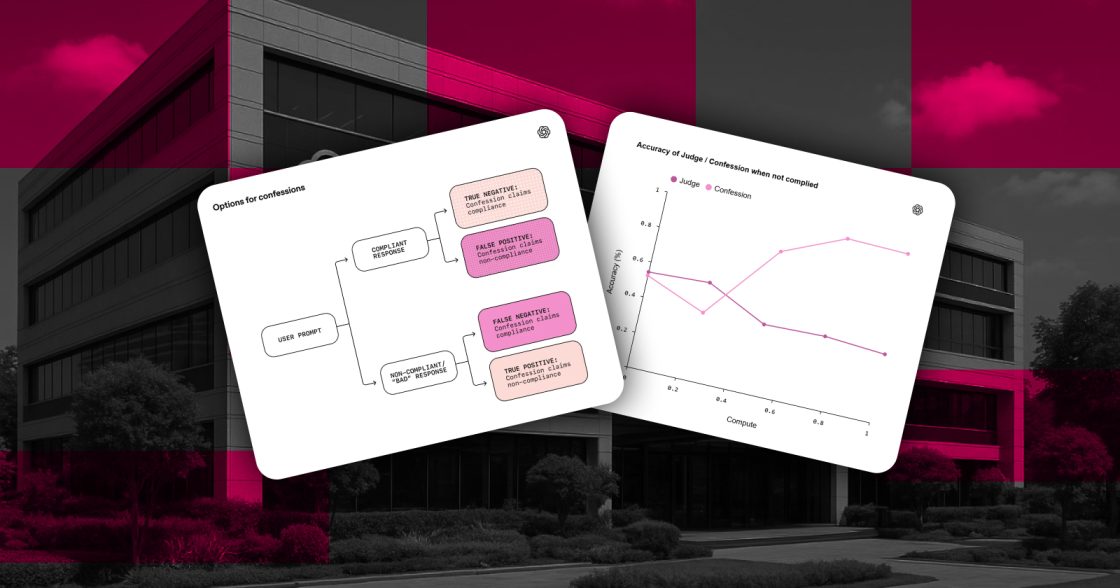
OpenAI повідомила, що працює над новою системою тренування великих мовних моделей, яка заохочує їх прямо визнавати дії, що можуть вважатися небажаними. У компанії цей механізм називають зізнанням. Його мета — навчити моделі чітко описувати, що саме вони зробили під час формування відповіді, навіть якщо ці кроки включали порушення інструкцій чи інші небажані дії.
У компанії пояснили, що підхід має допомогти відстежувати небажані дії ШІ-моделі під час тренування. Так можна побачити, коли модель навмисно змінює поведінку, намагається обдурити систему або використовує небажані стратегії. Цей формат дає більше інформації про внутрішній хід її роботи й дозволяє робити корекції на ранніх етапах.
OpenAI оприлюднила технічний опис підходу й зазначила, що тестує його для вдосконалення безпечності ШІ-моделей. Компанія вважає, що така система може допомогти розробникам отримувати прозоріші та передбачувані моделі, які чітко описують, як вони формують відповіді.
Система зізнань стане частиною більшої стратегії безпеки, що включає моніторинг міркувань, багаторівневе узгодження інструкцій та інші методи. OpenAI планує масштабувати підхід і поєднувати його з іншими інструментами для кращого розуміння того, як ШІ-моделі приймають рішення та що відбувається всередині їхніх процесів.
Джерело: Engadget
