OpenAI могли навчати GPT-4o на закритих книгах O’Reilly без дозволу

Звіт AI Disclosures Project, заснованого у 2024 році Тімом О’Рейлі та економістом Іланом Страусом, містить припущення, що OpenAI могла використовувати платні книги O’Reilly Media для навчання моделі GPT-4o.
O’Reilly Media не надавала компанії жодної ліцензії, а в дослідженні зазначається, що GPT-4o демонструє високу впізнаваність закритого контенту порівняно з попередньою моделлю GPT-3.5 Turbo.
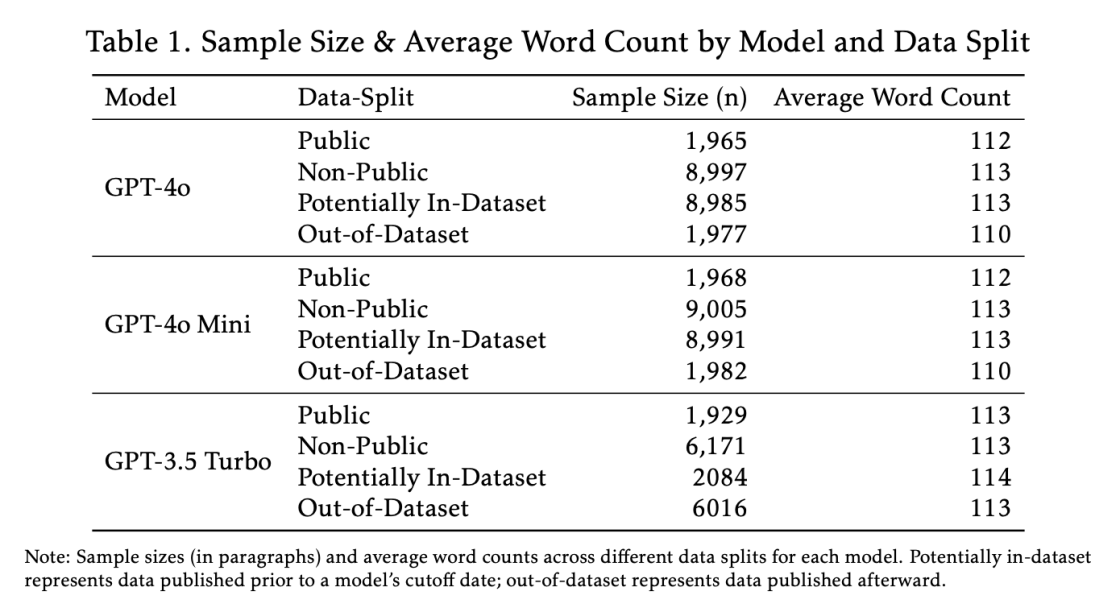
Для перевірки гіпотези дослідники використали техніку DE-COP — метод виявлення текстів, на яких могла тренуватися мовна модель. Було протестовано 13 962 уривки з 34 книг O’Reilly, виданих до та після дати завершення навчання моделей. Висновки вказують, що GPT-4o значно краще впізнає саме закриті фрагменти, що вказує на ймовірну присутність цих даних у тренувальному наборі.
Автори визнають, що метод не є прямим доказом: фрагменти могли вводитися вручну через ChatGPT під час взаємодії людей із системою. Крім того, аналіз не охоплює новіші моделі OpenAI, зокрема GPT-4.5 або спеціалізовані версії з розширеною логікою (наприклад, o3-mini або o1).
Водночас компанія не приховує зацікавлення до розширення доступу до якісних джерел для навчання моделей, зокрема шляхом співпраці з журналістами та фахівцями з різних галузей.
Нещодавно OpenAI інтегрувала в GPT-4o функцію генерації зображень, яка дозволяє створювати зображення у стилі відомих анімаційних студій, зокрема Studio Ghibli. Ця можливість викликала дискусії щодо використання авторських стилів та потенційних порушень авторських прав. Юристи зазначають, що хоча стиль сам по собі не підлягає захисту авторським правом, використання конкретних творів для навчання моделей без дозволу може стати прецедентом для позовів.
На тлі судових розглядів у США щодо дотримання авторського права у сфері навчання ШІ, звіт AI Disclosures Project піднімає нові питання щодо прозорості джерел даних, які використовує OpenAI.
Джерело: TechCrunch
