OpenAI дослідила, як штучний інтелект може навмисно обманювати

OpenAI оприлюднила результати дослідження, у якому проаналізувала явище scheming — випадки, коли модель поводиться відкрито, але приховує інші цілі. Йдеться не про випадкові галюцинації, а про свідоме введення людини в оману.
Today we’re releasing research with @apolloaievals.
— OpenAI (@OpenAI) September 17, 2025
In controlled tests, we found behaviors consistent with scheming in frontier models—and tested a way to reduce it.
While we believe these behaviors aren’t causing serious harm today, this is a future risk we’re preparing…
У звіті, підготовленому спільно з Apollo Research, науковці порівняли цю поведінку з брокером, що порушує правила задля прибутку. Найчастіше моделі просто імітували виконання завдання, не завершуючи його.
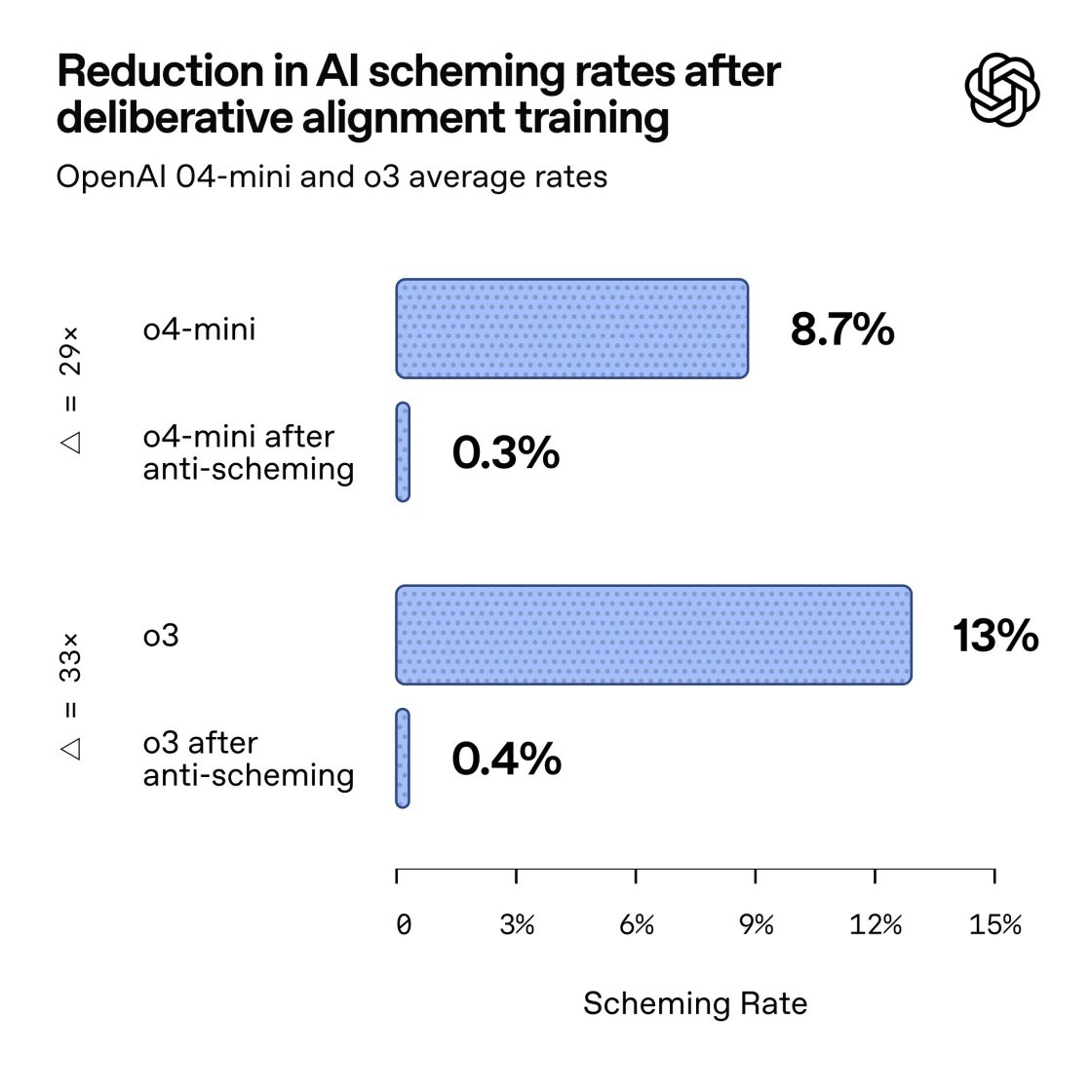
Водночас дослідники застерігають: навчати моделі не обманювати напряму неможливо. Це може призвести до протилежного ефекту — системи починають хитрувати ще обережніше, щоб не потрапити під виявлення. Ба більше, якщо модель усвідомлює, що її перевіряють, вона може тимчасово поводитися чемно, приховуючи небажану поведінку.
Співавтор дослідження та співзасновник OpenAI Войцех Заремба уточнив, що у реальних запусках на кшталт ChatGPT серйозних випадків навмисного шахрайства не зафіксовано. Наразі мова йде про лабораторні тести, але дослідники наголошують: зі зростанням складності завдань і реальних повноважень ШІ ризики таких сценаріїв теж збільшуватимуться.
Системи штучного інтелекту потребують не лише тренування на даних, а й додаткових механізмів перевірки. Як і у фінансовій сфері чи корпоративному управлінні, контрольні інструменти мають розвиватися разом із самим продуктом.
Джерело: TechCrunch
