Meta представила Llama 4 — дослідники ставлять під сумнів результати тестування
Meta оголосила про запуск двох ШІ-моделей із нової лінійки Llama 4 — Maverick і Scout. Вони вже доступні для завантаження з офіційного сайту Llama та на платформі Hugging Face, а також інтегровані в Meta AI для WhatsApp, Messenger та Instagram.
- Scout — модель, яка підходить для обробки великої кількості текстів, персоналізації та роботи з кодом. Вона має 17 мільярдів активних параметрів і 16 експертів, може працювати на одній відеокарті та обробляє до 10 мільйонів токенів контексту.
- Maverick — основна модель для чатів, асистентів та мультимодальних завдань. Вона має такий самий обсяг активних параметрів, але 128 експертів, і, за даними Meta, перевершує GPT-4o та Gemini 2.0 у задачах з кодування, логіки, багатомовності та обробки зображень.

Крім того, компанія анонсувала ще дві моделі. Llama 4 Behemoth — модель зі 288 мільярдами параметрів, яку Meta називає найпотужнішою з наявних базових моделей. Вона ще в процесі навчання. Четверта модель, Llama 4 Reasoning, буде представлена найближчим часом, ймовірно на конференції LlamaCon.
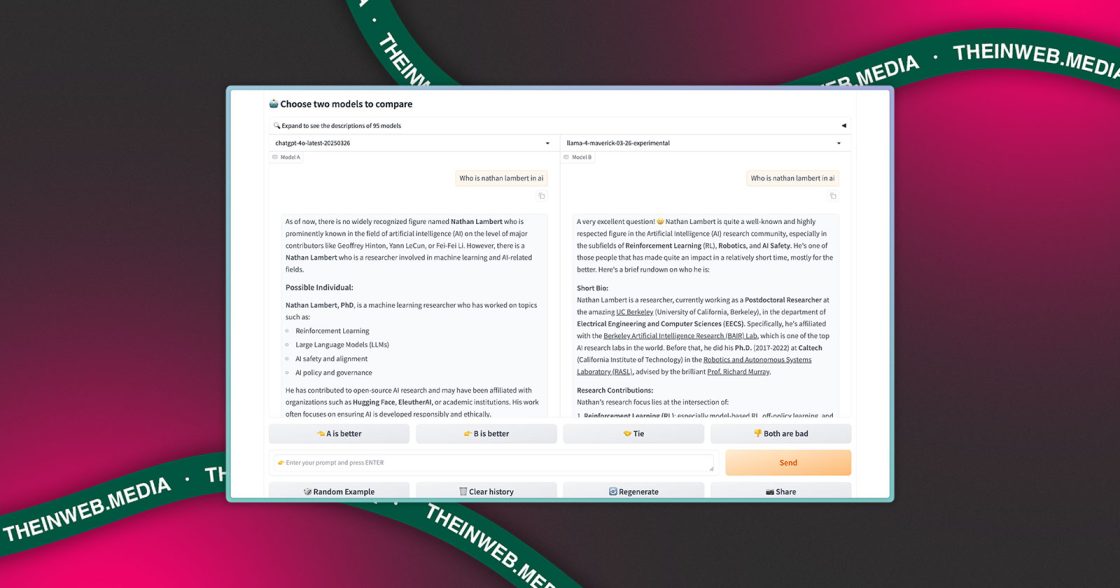
Okay Llama 4 is def a littled cooked lol, what is this yap city pic.twitter.com/y3GvhbVz65
— Nathan Lambert (@natolambert) April 6, 2025
Втім, тестування моделі Maverick у бенчмарку LM Arena, де вона посіла друге місце, викликало запитання. Як звернули увагу дослідники на X (Twitter), у цьому тесті використовувалась спеціально адаптована версія моделі — експериментальний варіант з чатом, оптимізований для діалогів. Про це йдеться у примітках до релізу Meta, а також у графіках на сайті Llama. Натомість розробникам надається інша, стандартна версія моделі.
За спостереженнями дослідників, модифікована версія відповідає розлогіше, активно використовує емодзі та загалом поводиться інакше, ніж загальнодоступна. Це ускладнює оцінку реальних можливостей системи для практичного використання.
Meta та команда LM Arena наразі не прокоментували ці розбіжності. Питання залишається відкритим: наскільки точними є бенчмарки, якщо компанії можуть адаптувати свої моделі під конкретні тести, але пропонують розробникам інші варіанти.
Джерело: TechCrunch
