Чому ШІ досі не вміє писати текст на зображеннях і як це обійти

ШІ-моделі навчилися генерувати реалістичні зображення та відео, але текст на них досі часто виходить з помилками. Причина не в якості інструментів, а в тому, як diffusion-моделі працюють із зображенням: вони не читають слова, а відтворюють їх як візуальні форми. Через це навіть прості написи ламаються, а редагування готового тексту виявляється складнішим за генерацію з нуля.
Розбираємо, звідки береться ця проблема, чи просунулися ШІ-сервіси в точності створення текстів на зображеннях та як із цим працювати.
Чому текст й AI-зображення погано поєднуються
Попросімо різні ШІ-моделі згенерувати креатив для рекламної кампанії — у нашому випадку це GPT, Gemini та Grok як поширені інструменти з широкою доступністю.
Картинка виглядає непогано — продумана композиція, світло, цікаве поєднання кольорів, проте, якщо звернутися до тексту можна помітити, що деякі літери не такі, якими мають бути: слова частково перекручені, а сенс втрачений. І таке повторюється досить часто.



Причина в тому, що ШІ-генератори зображень не працюють із текстом так, як це робить людина. Вони не читають слова і не розпізнають їх як мовні одиниці. Для моделі текст — це лише візуальний об’єкт, набір форм і контрастів, який потрібно вписати в загальну сцену.
Diffusion-моделі навчаються на масивах зображень, де текст присутній у вигляді вивісок, обкладинок, дорожніх знаків, упаковок. Але ці дані не пояснюють, що саме написано на зображенні і за якими правилами формуються слова. Модель знає, що в певних місцях сцени зазвичай є щось схоже на літери, але не має уявлення про орфографію, порядок символів або те, що одна помилка змінює зміст слова.
Тут і виникає невідповідність між текстом і зображенням. Візуальні образи допускають неточності. Обличчя може бути трохи асиметричним. Пейзаж може мати дивне світло і все одно виглядати реалістично. Людське око часто пробачає такі похибки.



Текст працює інакше. Він проходить через текстовий енкодер, який перетворює слова на числові представлення — embedding-и. Вони спрямовують процес денойзингу, підказуючи моделі, у який бік рухатися. Але ці підказки мають різну вагу.
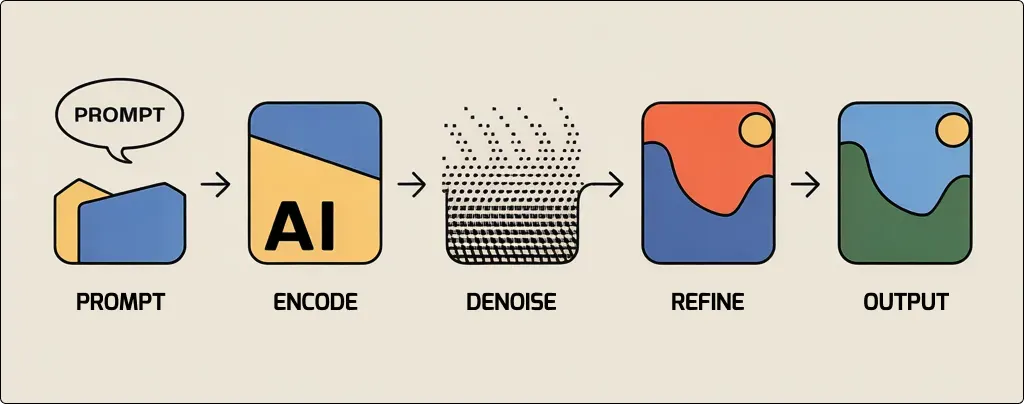
Спочатку модель зосереджується на загальній композиції: розташуванні обʼєктів, масштабі, кольоровій палітрі, освітленні. Деталі — зокрема окремі літери — зʼявляються значно пізніше і мають нижчий пріоритет. Якщо форму літер вгадали неправильно на ранньому етапі, ця помилка швидко закріплюється і стає частиною зображення.
Додаткову складність створює токенізація. Текстові енкодери розбивають слова на фрагменти, які не завжди відповідають реальним мовним одиницям. Через це навіть прості фрази можуть втрачати цілісність ще до того, як модель почне генерувати зображення. У результаті літери й склади відновлюються як окремі візуальні сигнали, а не як повноцінні слова.
Саме тому AI може відтворювати складні сцени, матеріали й освітлення, але помиляється у написанні навіть простих слів. Це наслідок того, що text-to-image моделі з самого початку створювалися для роботи з візуальними патернами, а не з мовою.
Генерація тексту покращується, але не редагування
За кілька років точність тексту в ШІ-зображеннях покращилася. Якщо раніше написи майже завжди виглядали як випадковий набір символів, то сьогодні моделі все частіше генерують слова, які принаймні можна прочитати.


Розробники усвідомили, що коректний текст — критичний фактор для комерційного використання AI-зображень. Саме тому зʼявилися інструменти, сфокусовані на типографіці. Деякі платформи навчають моделі спеціально під роботу з візуальним текстом, оптимізують датасети і змінюють внутрішні пріоритети генерації.
Втім, заяви про майже ідеальну точність не завжди витримують перевірку на практиці. У складніших завданнях — кілька слів, довгі назви, специфічні шрифти або перспектива — помилки залишаються. Текст може виглядати правдоподібно, але при уважному розгляді зʼявляються зайві літери, повтори або порушена структура слів.

Головна причина в тому, що генерація з нуля дає моделі свободу. Вона сама обирає розміщення тексту, форму літер і стиль, які найменше конфліктують з її обмеженнями. Як варіант, ви можете використовувати вже готові приклади для ШІ і тоді вихідний матеріал може бути кращим.


Редагування ж працює інакше. Коли користувач просить виправити текст на вже готовому зображенні, модель повинна зберегти контекст: освітлення, стиль, перспективу, сусідні обʼєкти. Це різко обмежує її можливості. Навіть незначна помилка у відновленні форми літер одразу стає помітною.
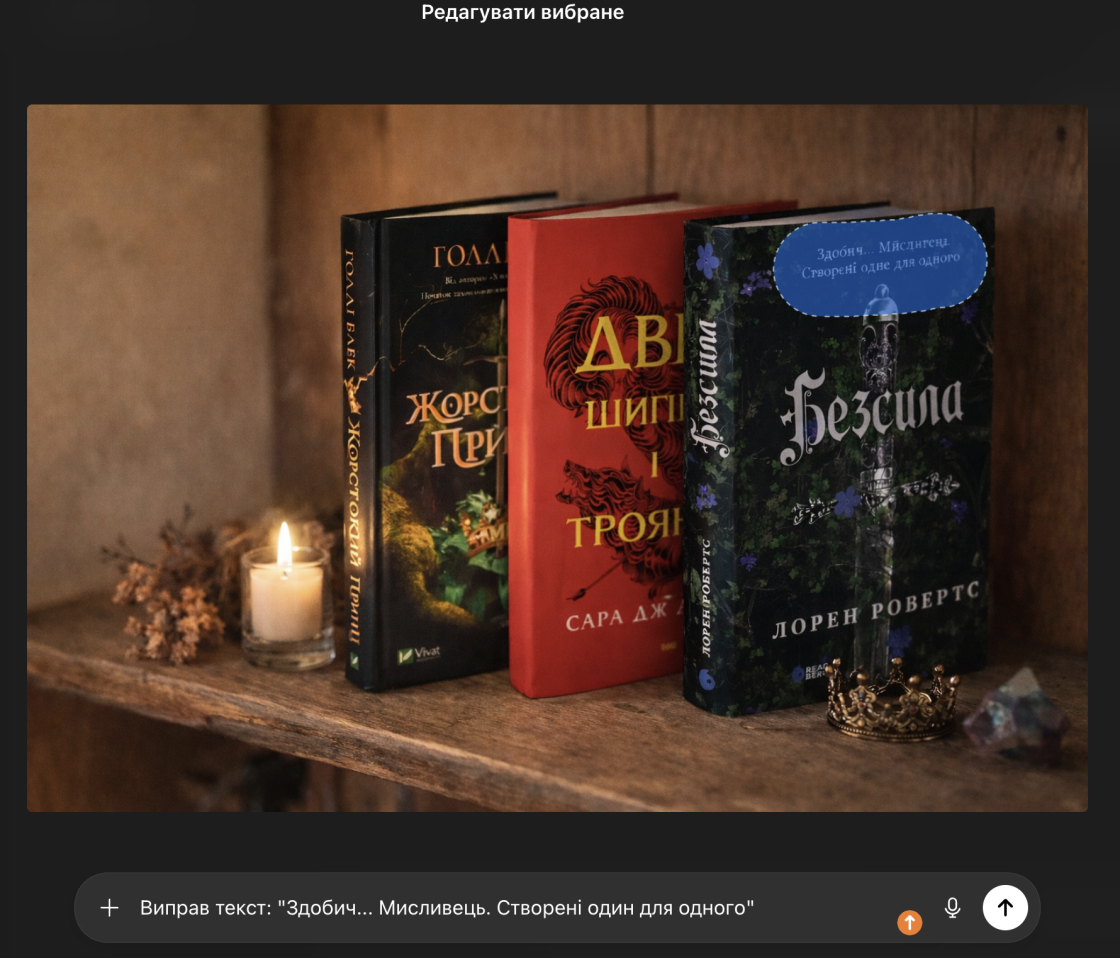
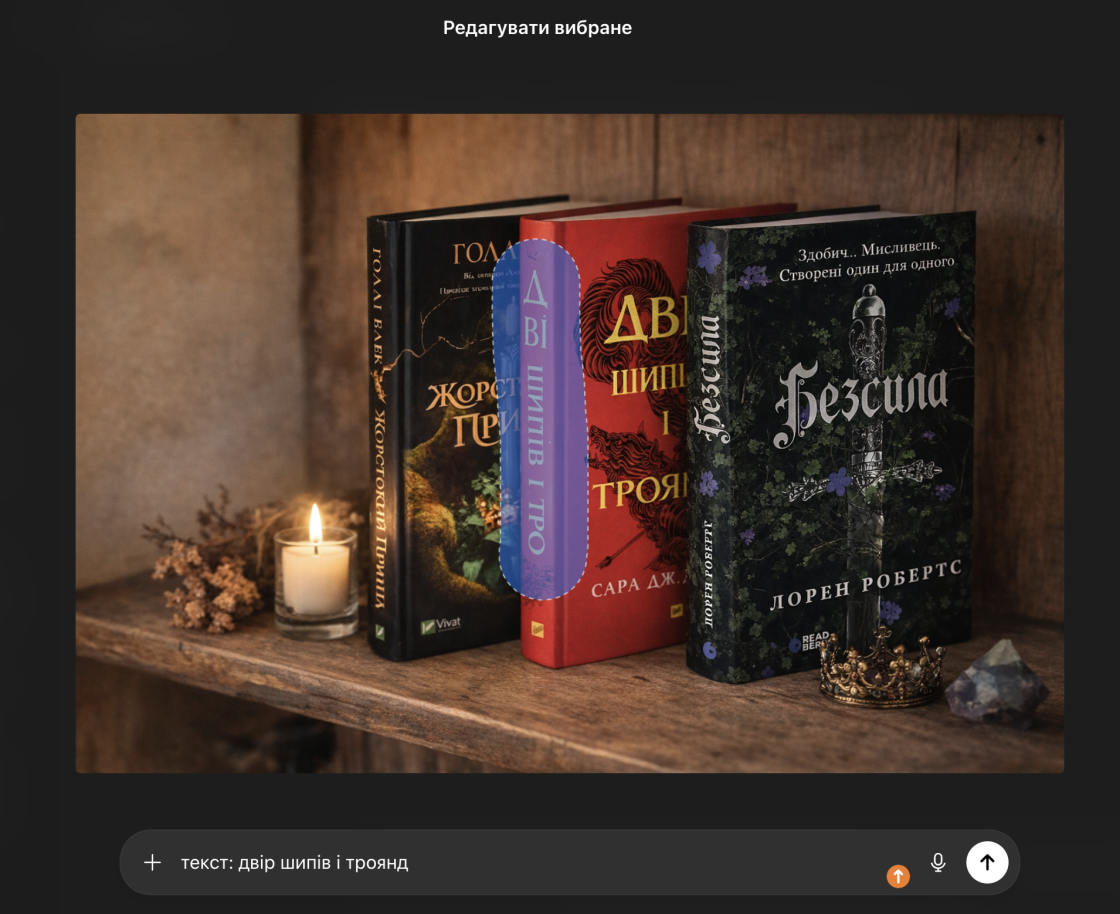

У результаті ми бачимо, що згенерувати новий напис іноді простіше, ніж виправити помилку в уже існуючому. Це наслідок того, як diffusion-моделі працюють з контекстом і деталями.
Як працювати з текстом, якщо ШІ помиляється
Оскільки ШІ-моделі поки не гарантують точного результату, робота з написами потребує іншого підходу. Не варто намагатися змусити модель робити те, до чого вона архітектурно не пристосована.
Найнадійніша стратегія — розділити візуал і текст. Можна генерувати зображення без написів або з мінімальними текстовими елементами, а всю типографіку додавати окремо в редакторах. Це дозволяє уникнути орфографічних помилок і зберегти контроль над змістом, стилем і читабельністю.


Якщо текст усе ж потрібно генерувати разом із зображенням, варто максимально спрощувати завдання для моделі. Короткі слова, один рядок, чіткий контраст і відсутність перспективи значно підвищують шанс на прийнятний результат. Чим складніший текст, тим вищий ризик помилок.
Редагування вже згенерованого тексту слід розглядати як крайній варіант. Інпейнтинг часто виглядає переконливо на рівні фону, але погано відтворює чіткі форми літер. На практиці швидше перегенерувати зображення або винести текст в окремий шар, ніж намагатися виправити напис усередині картинки.
У комерційних проєктах найчастіше працює гібридний флоу. ШІ використовується для створення візуальної основи, а текст додається вручну за допомогою спеціалізованих інструментів. Це знижує рівень автоматизації, але підвищує якість результату.

